Raft博士论文总结
Contents
目录
raft完全总结
raft核心基础
复制状态机
复制状态机包括 共识算法,状态机,日志。多个服务器的这三者组成复制状态机,形成raft group。
目的是为了让服务器形成一个单独的,高度可靠的状态机。
拜占庭将军问题
它们可确保在所有⾮拜占庭条件下的安全性(绝不会返回错误的结果),包括⽹络延迟,分区,数据包丢 失,重复和重新排序。

raft绝不会返回错误的结果。
拜占庭将军问题:在存在消息丢失的不可靠信道上试图通过消息传递的方式达到一致性是不可能的。拜占庭将军中可能存在叛徒,发送虚假的消息;即节点故意试图破坏系统,故意发送错误的或破坏性的响应。例如节点明明没有收到某条消息,但却对外声称收到了。这种行为称为拜占庭故障。在这样不信任的环境中需要达成共识的问题也被称为拜占庭将军问题。
高可用而不是完全可用
raft是会有可用性问题的。它是高可用(例如5个server宕机2个还可以用),不是完全可用。
CAP理论:CP
CAP理论:P一定成立,在C和A中只有一个能成立。
raft属于CP,保证一致性。
什么是AP,什么是CP,什么是CAP? - 终端研发部的文章 - 知乎 https://zhuanlan.zhihu.com/p/398801955
强一致性
强一致性、线性一致性、最终一致性:raft是强一致性,也即线性一致性。因为读的时候需要判断自己是否还是leader。但这是可以操作的,即leader直接返回结果而不需要确定,这就是A而失去了C(不好)。
持久化保存的状态 hardstate
hardstate,softstate,有哪些state需要持久化保存
tinykv的hardstate持久化了Term,Vote,Commit。前两者是为了避免在重启之后给同一个节点的一个任期投两次票。Commit在论文中说可以不持久化,重启是置位0。因为它只会暂时滞后于其真实值。选举领导者并能够提交新条⽬后,其 commitIndex 将增加,并将快速将该 commitIndex 传播给其关注者。不过把他持久化了更好吧。
RaftLocalState:用于存储当前 Raft 的 HardState 和 last Log Index和LastTerm。
在日志提交前持久化日志
每⼀个服务器也要在统计⽇志提交状态之前持久化该⽇志,这可以防⽌已经提交的条⽬在服务器重启时丢失或“未提交”。
状态机可以是易失性的,也可以是持久性的。重新启动后,必须通过重新应⽤⽇志条⽬(应⽤最新快照后;请参阅 第 5 章)来恢复易失性状态机。持久状态机在重启后已经应⽤了⼤多数条⽬。为了避免重新应⽤apply它们,其最后应⽤的索引lastAppliedIndex也必须是持久的(在tinykv中是在raft外面持久化的)。
这也是为什么将一个只读查询作为日志,commit后返回结果性能比较差的原因,因为日志在commit前要持久化才能返回同意。
leader不会覆盖或则和删除自己的日志
leader从来不会覆盖或者删除⾃⼰的⽇志。
log matching日志匹配特性
-
如果在不同的⽇志中的两个条⽬拥有相同的索引和任期号,那么他们存储了相同的指令。
-
如果在不同的⽇志中的两个条⽬拥有相同的索引和任期号,那么他们之前的所有⽇志条⽬也全部相同。
第⼀个特性来⾃这样的⼀个事实:领导者最多在⼀个任期⾥在指定的⼀个⽇志索引位置创建⼀条⽇志条⽬,同时⽇志条⽬在⽇志中的位置也从来不会改变。相当于(term, index) → instruction这个键值的映射的三个元素都固定了。
第⼆个特性由附加⽇志 RPC 的⼀个简单的⼀致性检查所保证。在发送附加⽇志 RPC 的时候,领导者会把新的⽇志条⽬紧接着之前的条⽬的索引位置和任期号包含在⾥⾯。如果跟随者在它的⽇志中找不到包含相同索引位置和任期号的条⽬,那么他就会拒绝接收新的⽇志条⽬。⼀致性检查就像⼀个归纳步骤:⼀开始空的⽇志状态肯定是满⾜⽇志匹配特性的,然后当⽇志扩展的时候⼀致性检查保护了⽇志匹配特性。因此,每当附加⽇志 RPC 返回成功时,领导者就知道跟随者的⽇志⼀定是和⾃⼰相同的了。
一致性检查:匹配nextIndex
在etcd或tinykv实现里,leader匹配follower的nextIndex是一步一步回退还是怎样?还是follower直接返回它上次commit的位置然后从这里开始(减少网络IO)?论文中讲了一种优化方式:跟随者可以包含冲突的条⽬的任期号和⾃⼰存储的那个任期的最早的索引地址。这样就变成每个任期需要⼀次附加条⽬ RPC ⽽不是每 个条⽬⼀次。在实践中,我们⼗分怀疑这种优化是否是必要的,因为失败是很少发⽣的并且也不⼤可能会有这么多不⼀致的⽇志。我的实现是在maybeDecrTo里,会将nextIndex-1。
选举限制
选举限制:通过在领导选举的时候增加⼀些限制来完善 Raft 算法。这⼀限制保证了任何的领导者对于给定的任期号, 都拥有了之前任期的所有被提交的⽇志条⽬。
这个限制是:RPC 中包含了候选⼈的⽇志信息,然后投票⼈会拒绝掉那些⽇志没有⾃⼰新的投票请求。
如何比较谁更新:Raft 通过⽐较两份⽇志中最后⼀条⽇志条⽬的索引值和任期号定义谁的⽇志⽐较新。
-
如果两份⽇志最后的条⽬的任期号不同,那么任期号⼤的⽇志更加新。
-
如果两份⽇志最后的条⽬任期号相同,那么⽇志⽐较⻓的那个就更加新。
不直接提交之前任期的日志条目:通过commit本任期的日志间接提交
论文 3.6.2 提交之前任期内的⽇志条⽬里讲的核心思想是:leader不会直接提交之前任期内的日志,哪怕这些日志已经被复制到了大多数了!而是会通过在经过一致性检查之后,commit自己这个任期的日志的时候,间接地把在自己日志中的之前任期的日志提交。commit自己任期日志是通过统计是否日志已经被复制到了大多数节点。
它用了一个图片讲了这个会发生错误的例子。即使一个日志被复制到了大多数节点,也是可能被覆盖的。所以leader不能通过判断之前任期的日志已经被复制到了大多数节点来提交他(除非增加更复杂的机制),而是要在提交自己任期日志的同时间接地把之前任期的日志提交。否则就可能会出现已经提交的日志被覆盖的错误!
复制到大多数节点的日志也可能被覆盖
一个问题是:在过程中,如果一个日志被复制到了大多数节点,那么它一定会在leader的日志中吗?答案是不一定。如3.6.2所说的那种情况。这个未提交的日志还可能被覆盖。
领导者完整性属性
安全性证明:leader中一定包含全部commit的日志
另一个问题:如果一个日志已经被commit,那么它一定会在leader的日志中吗?答案是一定。如果它不包含已经commit的日志,那么它不会被选出成为leader。3.6.3有一个安全性证明证明了这点。
新leader获取commitIndex
可以不持久化commit index,因为新leader可以通过发送一条no-op的日志来知道commitIndex。
领导者完整性属性可以保证领导者拥有所有已提交的条⽬,但是在任期开始之初,它可能不知道这些是谁。为了找出答案,它需要从其任期中提交⼀个条⽬。Raft 通过让每位领导者在任期开始时在⽇志中输⼊⼀个no-op条⽬来解决此问题。提交此空操作条⽬后,领导者的 commitIndex 将在其任期内⾄少与其他任何服务器⼀样⼤。
新leader之前如果是follower,那么它维护的commitIndex可能比实际的commitIndex跟小。
同理,如果一个新leader是重启后马上成为新leader的,他的commitIndex可能比实际的跟小。通过no-op条目的提交的到的commitIndex是最大的。
RPCs都是幂等的
Raft 的 RPCs 都是幂等的,所以这样重试(RPC)不会造成任何问题。
时间:安全性与可用性
Raft 的要求之⼀就是安全性不能依赖时间:整个系统不能因为某些事件运⾏的⽐预期快⼀点或者慢⼀点就产⽣了错 误的结果。但是,可⽤性(系统可以及时的响应客户端)不可避免的要依赖于时间。时间需要满足:⼴播时间(broadcastTime) « 选举超时时间(electionTimeout) « 平均故障间隔时间(MTBF)。
⼴播时间和平均故障间隔时间是由系统决定的,但是选举超时时间是我们⾃⼰选择的。⼴播时间⼤约是 0.5 毫秒到 20 毫秒,取决于存储的技术。因此,选举超 时时间可能需要在 10 毫秒到 500 毫秒之间。⼤多数的服务器的平均故障间隔时间都在⼏个⽉甚⾄更⻓,很容易满 ⾜时间的需求。
选票瓜分:超时
Raft 中的服务器通过等待选举超时来检测投票是否被⽠分。原则上,他们通常可以通 过计算授予任何候选⼈的选票来更快地发现甚⾄解决⽠分选票。我们选择不在 Raft 中对此做优化,因为它会增加 复杂性,但可能不会在实践中带来好处:在配置合理的部署中,很少有选票⽠分的情况。
保守策略:不直接提交先前任期的日志
领导者仅可以直接从当前任期提交条⽬,即使在某些特殊情况下它可以安全地提交先前任期的条⽬。应⽤⼀个更复杂的提交规则会有损易理解性并且可能没有显著的性能优化。在与其他⼈讨论 Raft 时,我们发现许多⼈不禁会想到并提出这样的优化,但是当⽬标是可理解性时,就应该放弃过早的优化。
领导迁移
领导迁移,三个步骤:
-
当前领导者停⽌接受新的客户请求。
-
当前领导者完整更新⽬标服务器的⽇志以使其与⾃⼰的⽇志匹配,使⽤第 3.5 节中描述的复制机制。
-
当前领导者将 TimeoutNow 请求发送到⽬标服务器。此请求与⽬标服务器的选举计时器触发具有相同的效 果:⽬标服务器开始新的选举(增加其任期并成为候选⼈)。
脑裂
不是啥特殊问题,例如:
5个节点的raft group,有五个节点A,B,C,D,E,A是leader。这时发生了网络分区,A和B在一个分区里,C,D,E在另一个分区里,相互不能通信。
A和B占少数,接收到读写请求时无法处理。
C,D,E占多数,超时后进行选举,选出leader例如C,可以处理读写请求。
此时,有A(旧leader)和C两个leader,于是发生脑裂。
当网络分区恢复之后,A发现C的term更大,于是成为follower。集群恢复正常。
prevote
在 PreVote 中,候选者需要确定自己能赢得大多数节点的投票,它才会把自己的 term 增加然后发起真正的投票。
如果没有prevote,当一个节点发生了网络分区,然后不断自增term,之后恢复,它会扰乱正常的raft group。因为它的term更大,所以leader会变成follower然后重新选举。但是其它节点不会投票给他,因为他的日志不会更新,这是因为它虽然term更大了,但是没有成为leader,所以日志还是落后的。但是它还是会扰乱一次集群,导致重新选举。
prevote的思想有点像2PC,第一阶段是准备。
更像网络中的阻止DDos攻击的那种机制,第一次握手不把socket放到半连接队列,也不保存到服务器上,而是返回一个类似cookie的东西,第三次握手的时候确认连接。
对称网络分区和非对称网络分区
关于 DDIA 上对 Raft 协议的这种极端场景的描述,要如何理解? - 多颗糖的回答 - 知乎 https://www.zhihu.com/question/483967518/answer/2097076504
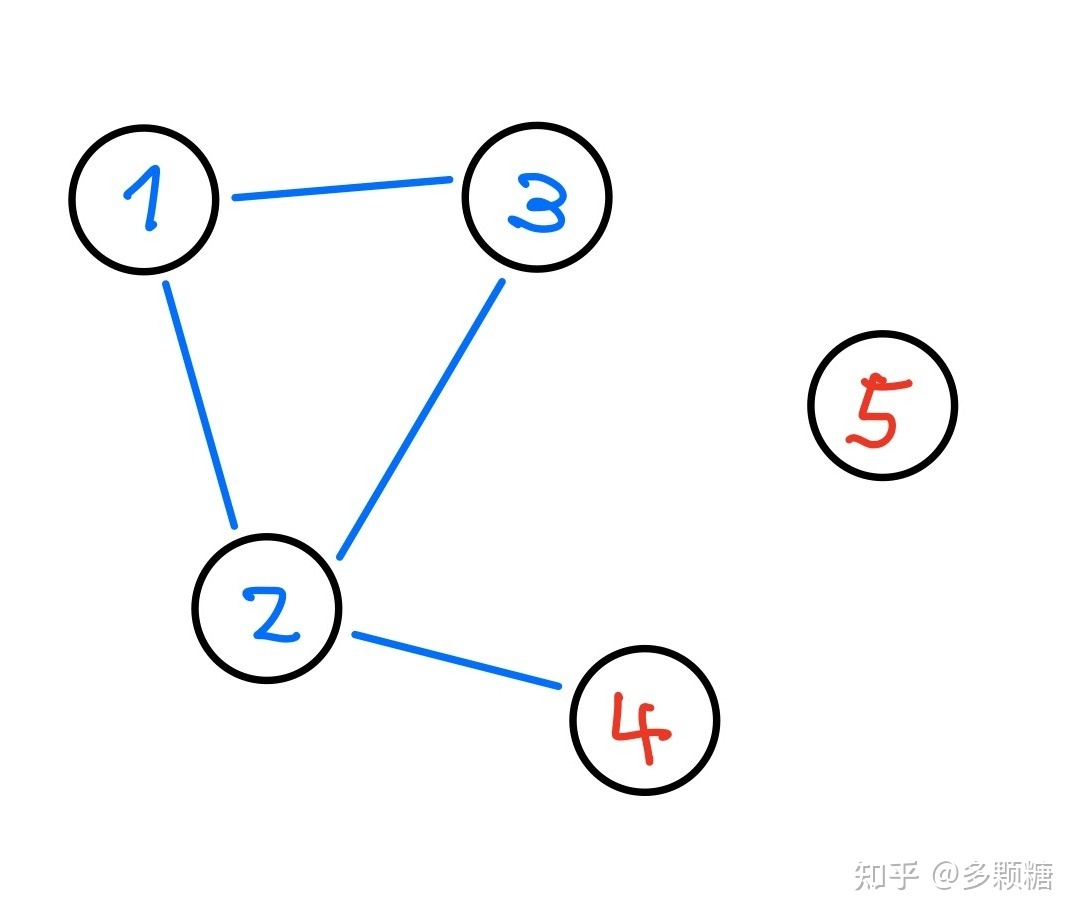
如图所示,按照默认的prevote,1,3无法成为leader,因为2会拒绝它的请求。而2不会发起投票,因为它有leader4一直在给他发心跳。这种鸟情况是非对称网络分区。
通过增加一个机制来解决:Leader 没有收到来自多数派节点的 AppendEntries 响应时就主动下台。
etcd 把这叫做 CheckQuorum,PreVote + CheckQuorum 可以解决该活性问题。
回答的作者写了一本书,可以看一下:https://book.douban.com/subject/35794814/
leader lease也能解决这个问题。因为续租不了了。
节点变更
Raft 限制了允许的更改类型:⼀次只能从集群中添加或删除⼀个服务器。
当向集群中添加或删除单个服务器时,旧集群的任何多数与新集群的任何多数重叠,这种重叠阻⽌了集群分裂成两个独⽴的多数派。因此,当只添加或删除⼀个服务器时,可以安全地直接切换到新配置。
而同时添加或删除2个服务器,可能导致分裂陈2个独立的多数派。
基本机制
当领导者收到从当前配置(C old )中添加或删除服务器的请求时,它将新配置(C new )作为⼀个条⽬添加到其⽇ 志中,并使⽤常规的 Raft 机制复制该条⽬。新配置⼀旦添加到服务器的⽇志中,就会在这个服务器上⽣效:C new 条⽬被复制到 C new 指定的服务器上,⽽⼤部分服务器的新配置⽣效被⽤于确定 C new 条⽬的提交。这意味着服务 器不会等待配置条⽬被提交,并且每个服务器总是使⽤在其⽇志中找到的最新配置。
⼀旦提交了 C new 条⽬,配置更改就完成了。此时,领导者知道⼤多数的 C new 指定的服务器已经采⽤了 C new 。它 还知道,没有收到 C new 条⽬的任意服务器都不能再构成集群的⼤多数,没有收到 C new 的服务器也不能再当选为 领导者。C new 的提交让三件事得以继续:
-
领导可以确认配置更改的成功完成。
-
如果配置更改删除了服务器,则可以关闭该服务器。
-
可以启动进⼀步的配置更改(指新的配置更改)。在此之前,重叠的配置更改可能会降级为不安全的情况。
如上所述,服务器总是在其⽇志中使⽤最新的配置,⽽不管是否提交了配置条⽬。这使得领导者可以很容易地避免重叠的配置更改(上⾯的第三项),⽅法是直到之前的更改的条⽬提交之后才开始新的更改。只有当旧集群的⼤多数成员都在 C new 的规则下运⾏时,才可以安全地开始另⼀次成员更改。如果服务器只在了解到 C new 已提交时才 采⽤ C new ,那么 Raft 的领导者将很难知道何时旧集群的⼤部分已经采⽤它。
新配置要删除某个旧节点时,在C new提交之前这个服务器不会被关闭吧。因为C new提交之前,它可能失败,因此它可能会取消配置更改,需要将节点回来。
不在配置的服务器的RPC
-
即使领导者并不在服务器的最新配置中,服务器依然接受它的 AppendEntries 请求。否则将永远不能将新服务器添加到集群中(它永远不会接受添加服务器的配置条⽬之前的任何⽇志条⽬)。
这是在新配置要加入新服务器的时候,leader用AppendEntries来传递配置给它。但是在此之前只接受配置条目,而不允许其它日志条目。
-
服务器还允许投票给不属于服务器当前最新配置的候选⼈(如果候选⼈有⾜够的最新⽇志和当前任期)。为 了保持集群可⽤,可能偶尔需要进⾏投票表决。例如,考虑将第四个服务器添加到三个服务器的集群中。如果⼀个服务器出现故障,就需要新服务器的投票来形成多数票并选出⼀个领导者。(而这个时候旧的某服务器可能还没收到配置日志,但是它可以投票)
增加节点
如果新加入的服务器一开始就有投票权,那么在两种情况下,直到新服务器的⽇志赶上领导者的⽇志之前,集群都将不可⽤。这两种情况是:
-
3节点变4节点时后,新节点日志落后,而有一个旧节点断了,那么需要等新节点追上日志后才可用。
-
3节点变4节点,又变5节点乃至6节点。导致需要先复制日志而状态机不可用。
因此,为了避免可⽤性缺⼝**,Raft 在配置更改之前引⼊了⼀个附加阶段,其中⼀个新服务器作为⽆投票权成员加⼊集群。 领导者复制⽇志条⽬到它,但出于投票或提交⽬的,尚未计⼊多数。**
⽆投票权服务器的机制(raft learner)可以用于优化读,可以保证最终⼀致性提供只读请求。
如果新服务器不可⽤或速度太慢以⾄于永远⽆法赶上,则领导者还应中⽌更改。
我们建议使⽤设定n轮日志复制机制来确定何时新服务器能够赶上并能被添加到集群中,每⼀轮开始时都将当前领导者⽇志中的所有⽇志条⽬复制到新服务器的⽇志中。例如设定10轮,如果最后⼀轮的持续时间少于⼀个选举超时,则领导者将新服务器添加到集群中;否则,领导者将因错误中⽌配置更改。
删除节点
删除节点时,如果要删除的是leader,那么先让leader禅让,然后再执行普通的删除。
破坏性服务器
指被删除的服务器不知道自己被删除了,然后会超时,于是增加term发起选举,不断重复导致正常的raft group不断重新选举。
用prevote解决:只有当候选⼈相信⾃⼰能从集群中的⼤多数⼈那⾥获得选票时,他才会增⻓任期编号并开始正常的 选举。
但光靠prevote不能完全解决。因为在『被删除的服务器的⽇志⽐⼤多数集群的⽇志更新』的情况下,预投票检查没有帮助。例如刚刚leader刚刚产生Cnew的时候。
Raft 的解决⽅案是使⽤⼼跳来确定何时存在有效的领导者。当这个破坏性服务器像Cnew配置的服务器请求投票时,即使他的日志可能更新,也不一定给他投票。而是检查一下服务器上次收到来自leader的心跳到现在的时间间隔,是否大于最小选举超时时间。如果不是,那么直接拒绝投票。
这个机制会和领导禅让冲突,因为禅让时leader的心跳是正常的。但是领导禅让这里可以在requestVote里添加特殊字段,让它有权请求投票。
这个机制可以解决很多"破坏性服务器"的问题,不只是节点删除这里,例如:
-
一个节点发生了网络分区,不断超时自增term后网络恢复了。之前是通过prevote解决这个问题,但是用上面这个方式也可以避免这问题。
-
假设有5个节点,刚开始5个节点两两是联通的。但是突然leader和某一节点X之间出现了网络分区,X收不到心跳就会发起选举。而其它三个节点因为能够正常收到心跳,所以不会给他投票,所以这个服务器不会影响正常的leader运行。
但是我有个疑问:这个发生网络分区的服务器term会不断自增且大于正常leader,后面他不影响正常leader了,它如何回到raft group?总不会他的term回到和leader一样吧(减小了)?
no!在prevote里,prevote阶段它没有收到大多数节点的同意的话它的term是不会增加的!所以term不会更大!所以可以直接回来!
所以这个投票的时候增加的心跳超时验证机制应该配合prevote来使用!
联合共识
一种可以灵活更改配置的方法。较为复杂,不建议使用。
联合共识是一种过渡状态:
-
⽇志条⽬被复制到所有包含新配置或旧配置的服务器。
-
来⾃任⼀配置的任何服务器都可以作为领导者。
-
协议(⽤于选举和条⽬提交)要求新⽼配置各占多数。
联合共识允许各个服务器在不同的时间在不同的配置之间转换,且不会影响安全性。 此外,联合共识允许集群在 整个配置更改期间继续为客户请求提供服务。
单节点变更的bug
TiDB 在 Raft 成员变更上踩的坑 - drdr xp的文章 - 知乎 https://zhuanlan.zhihu.com/p/342319702
参考:https://www.inlighting.org/archives/raft-membership-change

-
t₁:
abcd4节点在 term 0 选出leader=a, 和2个followerb,c; -
t₂:
a广播一个变更日志Cᵤ, 使用新配置Cᵤ, 只发送到a和u, 未成功提交; -
t₃:
a宕机 -
t₄:
d在 term 1 被选为leader, 2个follower是b,c; -
t₅:
d广播另一个变更日志Cᵥ, 使用新配置Cᵥ, 成功提交到c,d,v; -
t₆:
d宕机 -
t₇:
a在term 2 重新选为leader, 通过它本地看到的新配置Cᵤ, 和2个followeru,b; -
t₈:
a同步本地的日志给所有人, 造成已提交的Cᵥ丢失.
作者给出了这个问题的修正方法, 修正步骤很简单, 跟Raft的commit条件如出一辙: 新leader必须提交一条自己的term的日志(如commit 一条 no-op 的日志), 才允许接变更日志:
The solution I’m proposing is exactly like the dissertation describes except that a leader may not append a new configuration entry until it has committed an entry from its current term.
品完后笔者一拍大腿: 这个修正实际上就是将单步变更升级成了joint consensus, 本质上都变成了: 一条变更在旧的配置中必须通过quorum互斥, 只能有1个变更被认为是committed. 单步变更需要一条业务日志或一条NoOp日志完成这件事情, joint consensus直接完成了这件事情:
所以etcd的raft实现中都要求在成为leader之后进行一个no-op日志的提交。
日志压缩:snapshot
为了避免raft的日志无限增长,需要进行日志压缩。如果没有压缩⽇志的⽅法,最终将导致可⽤性问题:即服务器存储空间不⾜,或者 启动时间太⻓。
每个服务器可以独立地压缩其日志。而不需要leader的控制。
基于内存的状态机创建快照
在创建快照时,整个当前系统状态被写⼊稳定存储上 的快照,然后丢弃该点之前的所有⽇志。在 Chubby 和 ZooKeeper 中使⽤这种鸟方法,并且在 LogCabin 中也实现了它。
每个服务器都独⽴拍摄快照,仅覆盖其⽇志中的已提交条⽬。⼀旦状态机完成了快照的写⼊,就可以将⽇志截断。
Raft 还需要保存快照最后包含的索引和任期。
生成快照的方法
需要使状态机的状态一致(不能变化)。有两种方法:
-
使用操作系统的写时复制。在 Linux 上,内存状态机可以使⽤ fork 来复制服务器整个地址空间。⼦进程可以写出状态机的状态并退出,⽽⽗进程则继续为请求提供服务。LogCabin 的实现当前使⽤了此⽅法。
-
状态机可以⽤不可变的(功能性)数据结构来⽀持这⼀点。因为状态机命令不会修改适当的状态,所以快照任务可以保留对某个先前状态的引⽤,并将其⼀起写⼊快照中。
服务器需要额外的内存来并创建快照,应该提前计划和管理这些内存。在拍摄快照期间内存容量耗尽的不 幸事件中,服务器应停⽌接受新的⽇志条⽬,直到完成快照为⽌。这将暂时牺牲服务器的可⽤性。
LogCabin ⾸先将每个快照写⼊⼀个临时⽂件,然后在写⼊完成并刷新到磁盘后重命名该⽂件。
何时生成快照
⼀种简单的策略是在⽇志达到固定⼤⼩(以字节为单位)时拍摄快照。
更好的⽅法是将快照的⼤⼩与⽇志的⼤⼩进⾏⽐较。如果快照⽐⽇志⼩很多倍,则可能值得生成快照。但是,在生成快照之前计算快照的⼤⼩可能既困难⼜麻烦,给状态机带来了很⼤的负担。
幸运的是,使⽤上⼀个快照的⼤⼩⽽不是下⼀个快照的⼤⼩可以得到合理的⾏为。⼀旦⽇志的⼤⼩超过前⾯快照的⼤⼩乘以⼀个可配置的扩展因⼦,服务器就会拍摄快照。例如,扩展因⼦ 4 导致约 20% 的磁盘的带宽⽤于快照(对于快照的每 1 字节,将写⼊ 4 字节的⽇志条⽬),并且存储⼀个快照(旧的快照,⽇志 4 倍,和新写⼊的快照)需要⼤约其 6 倍的磁盘容量。
基于磁盘的状态机创建快照
对于基于磁盘的状态机,作为正常操作的⼀部分,系统状态的最新副本将保留在磁盘上。因此,⼀旦状态机 反映了对磁盘的写⼊,就可以丢弃 Raft ⽇志,并且仅在将⼀致的磁盘映像发送到其他服务器时才使⽤快照。
尽管他们总是在磁盘上有快照, 但他们也在不断对其进⾏修改。因此,他们仍然需要写时复制技术,以便在⾜够⻓的时间内保持⼀致的快照。磁盘格式⼏乎总是划分为逻辑块,因此在状态机中实现写时复制应该很简单。
增量式日志压缩方法
配合leveldb这种LSM-Tree结构。
leveldb的内容被持久化到了磁盘,以SST这种不可修改的格式。因此可以传输SST文件作为快照。这种快照是增量式的。
每段SST文件都对应一段日志。
但会造成日志空洞。
基于领导者的方法
每个服务器不独立地进行日志压缩,而是由领导者进行,然后将压缩的快照以日志的形式通过AppendEntries复制给follower。
极小状态机的日志压缩方法
如果状态机极小,例如只有1M,那么适合这种方法。
把状态机的快照以日志条目的形式复制到follower,而不需要额外的RPC机制。
客户端
将请求路由到领导者
有多种方式:
-
客户端随机连接一个服务器。⾮领导者服务器拒绝请求并将领导者的地址 (如果知道)返回给客户端。这允许客户端直接重新连接到领导者。
-
客户端随机连接一个服务器。服务器可以将客户的请求代理给领导者。
处理重复的查询请求
服务器必须过滤掉重复的请求。基本思想是服务器保存客户端操作的结果,并使⽤它们跳过重复的相同请求。为了实现这⼀点,每个客户端都被赋予唯⼀的标识符,并且客户端为每个命令分配唯 ⼀的序列号。每个服务器的状态机为每个客户端维护⼀个会话。该会话跟踪为客户端处理的最新序列号以及相关的响应。如果服务器接收到已经执⾏了序列号的命令,它将直接响应⽽⽆需重新执⾏该请求。
客户端的会话不只跟踪客户端最近的序号和响应,⽽是包含了⼀组序号和响应。客户端每次请求都将包括其尚未收到响应的最低序列号,然后状态机将丢弃所有⽐之较低的序 列号响应。
只读查询优化
只读的客户端命令仅查询⽽不会改变复制的状态机。
read-only log read
提交⼀个只读查询的条⽬到⽇志中。需要用到AppendEntry,性能较差,因为涉及同步磁盘写⼊。
readindex
-
如果领导者尚未将其当前任期的条⽬标记为已提交,则它将等待直到它已经完成为⽌。领导者完整性属性可以保证领导者拥有所有已提交的条⽬,但是在任期开始之初,它可能不知道这些是谁。为了找出答案,它需要从其任期中提交⼀个条⽬。Raft 通过让每位领导者在任期开始时在⽇志中输⼊⼀个no-op条⽬来解决此问题。提交此空操作条⽬后,领导者的 commitIndex 将在其任期内⾄少与其他任何服务器⼀样⼤。
-
领导者将其当前 commitIndex 保存在局部变量 readIndex 中。这将⽤作查询所针对的状态版本的下限。
-
领导者需要确保⾃⼰没有被不知道的新领导者所取代。它发出新⼀轮的⼼跳,并等待⼤多数集群成员的确认。收到这些确认后,⼀旦收到这些确认,领导者知道在发送⼼跳的那⼀刻不可能有⼀个⽐起任期⼤的领导 者。因此,当时的 readIndex 是集群中任何服务器看到的最⼤提交索引。
-
领导者等待其状态机⾄少应⽤到 readIndex;这⾜够满⾜线性化要求。
-
最后,领导者针对其状态机发出查询,并向客户端回复结果。
readIndex的意义在于,他是查询来到的时间点的commitIndex;而查询是从状态机中进行查询,因此需要等状态机apply这个readIndex的日志到状态机(先持久化再commit再apply)。这样,查询的结果就不会更旧(而是更新)。
所以查询到的数据一定是持久化了的,且commit了的,且apply到了状态机的。
follower read
一种基于readindex的优化。
Region 的 follower 节点需要使用 Raft ReadIndex 协议确保当前读请求可以读到当前 leader 上已经 commit 的最新数据。因此如果follower日志落后还需要等待日志同步,commit并且apply之后才可以返回结果。
follower read 并没有提升延迟,而是主要是提升了整体吞吐,缓解了leader的压力。以前所有的数据都需要通过 leader 返回,而现在可以通过 follower 返回,分散开了。但是会增加一个从 follower 向 leader 请求最新 commit index 及返回的过程,所以延迟并不会有多少优化。
follower可以进行负载均衡。
lease read
lease read的时间:https://www.cnblogs.com/lizhaolong/p/16437165.html
leader 会获取一个 lease,然后告知所有的 follower,这期间内不可以选出新的 leader**,lease 需要获得大多数节点同意**。而即使 leader 网络分区了也没关系,因为在 lease 内是不会有新的leader 被选出来的。
租期通过心跳进行续租。
需要保证 Leader 的租约比重选新的 Leader 的 Election Timeout 短。
在leader的租期内可以直接返回commitIndex的结果,而不需要向其它follower确认自己是否是有效的leader。租约到期续租失败那么自己就不是有效的leader了。
合并读请求(和前面的不冲突)
论文中说LogCabin 在领导者上实现了readindex,并且在⾼负载的情况下通过积攒多个只读查询来分摊开销。
Leader election evaluation
一个特殊的第9章,讲的是leader选举的时间(性能)问题。
不过比较复杂,以数学模型进行的计算,有很多公式和推导。
没有split votes的情况最快多久能选出leader
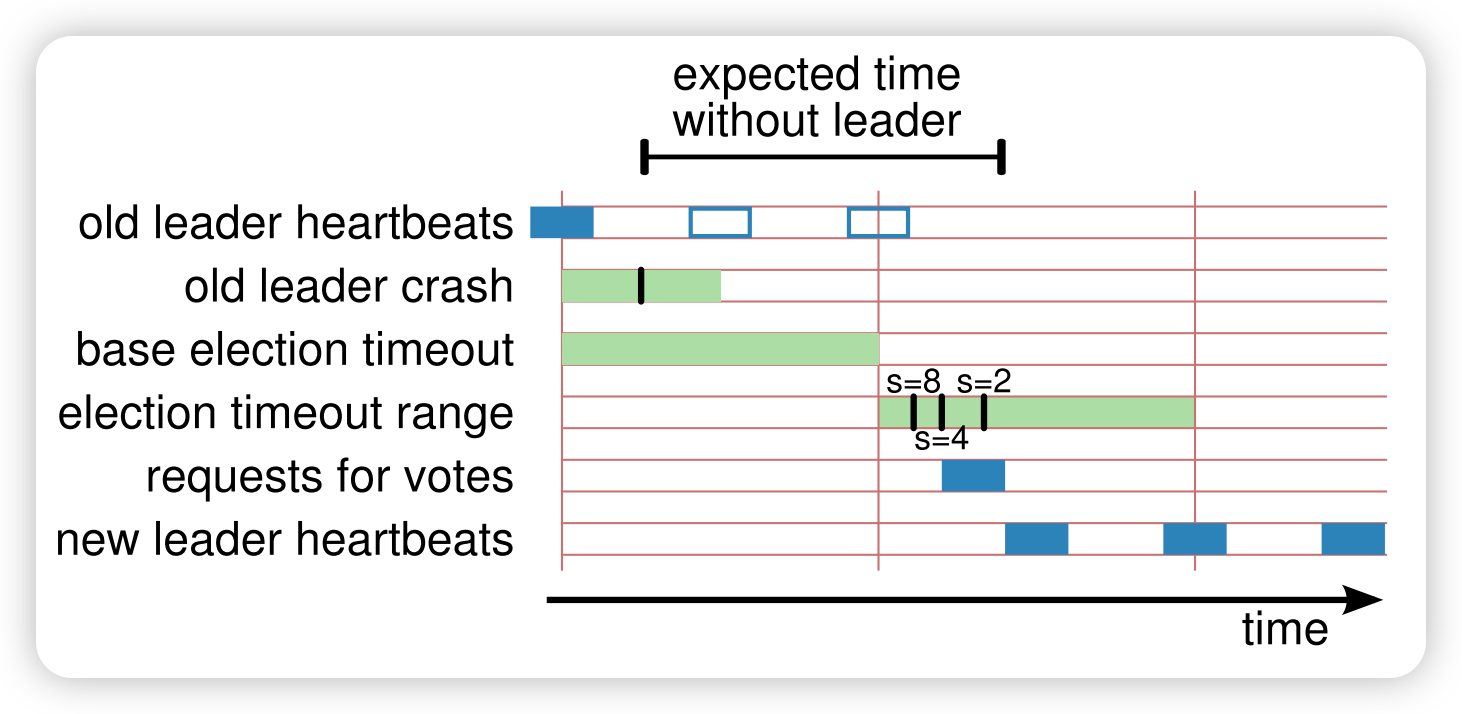
很复杂,说一下流程:
old leader发送最后一个心跳后,发生了crash。其它follower在接收到这个心跳后重置election timeout,第一个follower超时后,发起选举。选举的广播的延迟受到集群网络性能的限制,在收到大多数节点的同意后成为leader,然后发起新的心跳。
split votes有多普遍?
它的数学模型和计算非常复杂,不看呜呜
当发生split votes时,raft多快能选出leader
完整的raft算法能否在真实网络中选出一个领导者?
有点复杂。99%的都在1s之内吧。
当日志不同时会发生什么?
防止在服务器重新加入集群时发生中断
就是prevote解决的那个问题
其它优化
parallel raft
如何评价 PolarFS 以及其使用的 Parallel Raft 算法? - 暗淡了乌云的回答 - 知乎 https://www.zhihu.com/question/278984902/answer/562927275
他说:
Parallel Raft 就是 Raft 框架下的 Multi-Paxos [1]。Parallel Raft 通过借鉴 Multi-Paxos(1)乱序确认(2)乱序提交 实现日志复制的性能优化;通过 Raft 大框架保证协议正确性,并根据实际应用场景实现(3)乱序 Apply。

Raft 和 Multi-paxos 中提交 commit 的含义是不一样的: 在 Raft 中,commit 的日志就可以 apply,但是 Multi-Paxos 中并不行,以图下半部分的 Multi-paxos Log 的acceptor 2 为例,尽管 index=8 的 log 已经 commit 了,但是它并不能 apply,因为其前面还存在空洞,实际上在 multi-paxos 中只有 <= commit index 的 log 才能被 apply,图中 Leader,acceptor 1,acceptor 2 的 commit index 分别为 10,7 和 6。实际上看到这里,你会发现 Multi-paxos 这种允许日志空洞的日志复制是不是很像网络里面的滑动窗口。
Author 姬小野
LastMod 2022-11-04