CMU 15-445: project3 - Query Execution
Contents
概述
project地址: https://15445.courses.cs.cmu.edu/fall2021/project3/
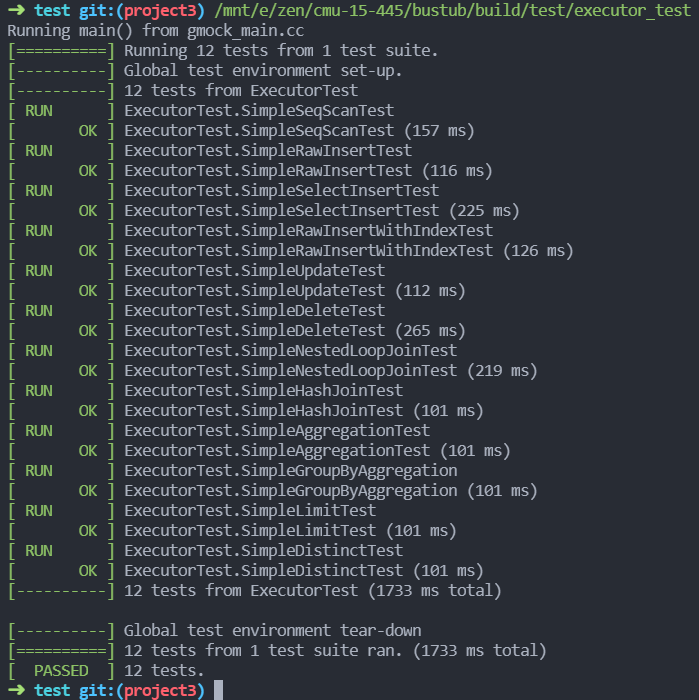
测试方式
|
|
只有一个task, 不过这个task非常的长, 因为有要实现很多东西, 各种查询执行的模块如Insert, Select, 聚合等等, 不过它实现好了火山模型, 所以做这个的时候应该会比较有意思而且比较快, 而且可以从它这么好的源码来学习了解实际火山模型, 非常nice.
主要是实现以下三类操作:
- Access Methods: Sequential Scan 顺序扫描
- Modifications: Insert, Update, Delete 对数据的修改
- Miscellaneous(混杂的): Nested Loop Join, Hash Join, Aggregation, Limit, Distinct
看起来不错, 这些内容涵盖了miniob比赛的好多题了, 不过做起来应该会比较快.
因为DBMS(还)不支持SQL,所以您的实现将直接操作手写的查询计划… 且看它执行计划是咋样的.
Volcano model是迭代器模型的一种实现(还可以有其他类型的实现).
每个execuator都实现了Next()方法, 当调用它的Next()时, 要么返回a single tuple, 要么返回一个指示没有结果的东西. 使用这种方式, 每个execuator会实现一个循环来调用它的children的Next方法, 从而得到tuple并一个一个地处理他们.
每个execuator的Next()方法除了返回tuple还会返回一个RID
TASK #1 - EXECUTORS
下面是相关执行器的头文件(9个, 好多, 不过实现了几个其他相似的就很好实现了, 毕竟都是迭代器模型); 还有许多其他对应的plan头文件和cpp实现文件.
src/include/execution/executors/seq_scan_executor.hsrc/include/execution/executors/insert_executor.hsrc/include/execution/executors/update_executor.hsrc/include/execution/executors/delete_executor.hsrc/include/execution/executors/nested_loop_join_executor.hsrc/include/execution/executors/hash_join_executor.hsrc/include/execution/executors/aggregation_executor.hsrc/include/execution/executors/limit_executor.hsrc/include/execution/executors/distinct_executor.h
需要为他们实现Init和Next, Init用来初始化内部状态, Next则是迭代器接口, 除了要返回tuple, 还要返回一个相关的RID(==但是这个RID不是只有存在的数据才有吗? 如果我是聚合来的, 我这个数据怎么会有RID呢?==)
代码阅读与解析
需要了解一下三个文件夹的代码:
- src/include/execution/executors/*: 定义了执行器的头文件
- src/include/execution/plans/*: 定义了执行计划plan的头文件
- src/execution/*: 每个执行器的具体实现
这里首先着重了解 abstract_plan.h和abstract_executor.h; 前者是一个标识执行计划的基类, 其他的执行计划都继承了它, 而后者则是执行器的基类; 看源码的话发现有一定的相似, 这两者是什么样的调用关系呢?
plan nodes被组织成树形结构, 每个node有一系列的子节点.
具体到insert_executor.h和insert_plan.h, 发现insert_executor中有一个成员变量是InsertPlanNode *, 说明每个执行器节点对应一个plan节点. 而executor中并没有包括数据, 而是只有计算过程, 具体的数据例如一个表头output_schema是abstract_plan的成员变量, 而行数据values(二维vector)则是在具体的insert_plan.h中.
分析测试代码
测试代码中手动创建了一个执行计划, 并且在执行引擎调用Execute的时候调用CreateExecutor方法创建了Executor树, 这个函数可以重点看一下. 在CreateExecutor方法中, 传递进去的plan本身是一个树形结构, 因此根据其type会创建不同类型的Executor, 而plan本身也有child plan, 可以用来递归调用CreateExecutor, 从而形成一颗执行器树结构.
在Execute内部, 则是通过以下方式来执行, 因此, 重点就是实现每一类Executor的Init函数和Next函数. 而在SeqScan的执行计划中, 比较简单, 他没有child, 其他也没有child的还有IndexScan; 对于Join类型的Executor, 他们有更多的子节点(left, right).
|
|
现在让我有点困惑的是, 这里都没有Insert任何数据, 那么我要获取什么数据呢?
并不是! 数据是在表中, 而表是在src/catalog/table_geneartor.cpp中生成的, 可以看到各种表. 例如他们的size
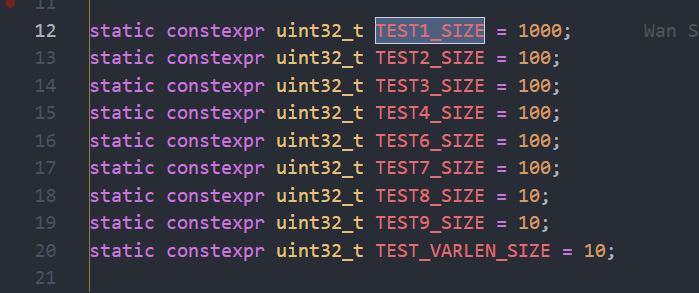
数据操作
每个操作都需要有的一些成员变量来进行具体的操作. 例如SeqScan就需要有很多的底层数据的操作, 需要用到TableHeap的API
|
|
这个TableHeap应该就是代表堆表结构, 它实现了一些方法对表进行访问, 例如
- GetTuple
- InsertTuple
- UpdateTuple
- Delete(MakeDelete, rollback) 等等
在第一个seq_scan_executor中, 就是通过循环调用GetTuple来获取表中的数据.
SeqScan
第一个功能, 是实现顺序scan
RawInsert
插入raw数据, 和它对比的是插入 select子查询的数据.
通过测试
Author 姬小野
LastMod 2021-11-12