CMU 15-445: project1 - buffer pool
Contents
前言
简单记录一下做这个lab遇到的一些坑, 以及主要思路.
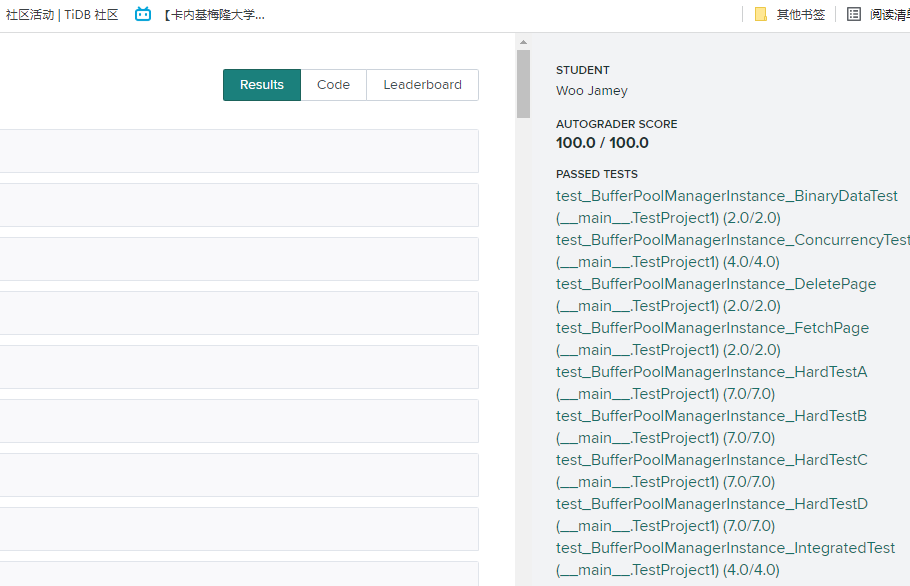
刚开始做这个lab的时候, 是只在本地通过了单元测试, 然后觉得就对了. 之后了解到这个lab可以在gradescope进行线上测试, 于是开始提交, 结果一直出现编译错误, 因为有时候push所有的文件, 有时候又漏掉了某些文件. 后来又看到lab文档上说明了在gradescope测试要上传的文件, 这才正确提交
|
|
刚提交时分数只有20分, 晕, 于是反复地修改, 提交, 得到反馈, 再修改, 提交, 最后终于拿到了100分. 分数也从20 -> 30 -> 32 -> 42 -> 68 -> 67 -> 97 -> 100, 不断地发现错误和解决错误.
TASK #1 - LRU REPLACEMENT POLICY
LRU替换策略是project1中三个子模块地第一个, 是实现一个LRU策略(但实际上, 和通常以为的LRU的操作有点细微的差别).
这个部分需要实现以下几个接口:
-
Victim
语义是需要释放一个位置, 并将释放出来的这个frame_id返回
-
Pin
pin表示这个page正在被使用, 那么不能被LRU替换出去, 因此表现为将这个page从lru列表中删除, 从而避免被淘汰.
-
Unpin
unpin则和pin相反, 代表一个page的pin_count为0了, 然后加入到LRU中等到被淘汰.
在这个实验中, 和常规LRU有所区别的是, 对一个已存在在LRU列表中的page多次Unpin时, 并不会将它移到后面(即最新访问), 而是直接忽略它. 因为似乎在bustub中, 一个page是不会被连续unpin的. 不过文档中并没有相关描述, 这个语义是通过单元测试推断来的.
还有要注意的点是, LRUReplacer需要使用latch_来对临界区进行保护.
对于临界区, 可以使用下面的方式
|
|
避免因为忘记释放锁而造成的死锁问题, 它是一种资源分配时初始化(RAII)方法, 在对象析构的时候自动释放锁. 跟go语言的
|
|
很像, 而且还更方便一点.
LRU算法较简单, 注意一些细节即可通过测试
TASK #2 - BUFFER POOL MANAGER INSTANCE
这个部分是最复杂的部分, 需要注意很多细节, 主要需要实现
-
FlushPgImp
将指定的page写入磁盘
-
FlushAllPgsImp
将所有page刷盘
-
NewPgImp
获取一个新的page, 并且返回page id. page id需要从AllocatePage()获取.
-
Make sure you call AllocatePage!
-
If all the pages in the buffer pool are pinned, return nullptr.
如果所有的pages都 pinned, 即 replace_里没有元素了
- Pick a victim page P from either the free list or the replacer. Always pick from the free list first.
始终优先从 free list 获取页面; 如果获取不到, 就从LRU中淘汰一个页面然后利用(注意对脏页要落盘)
- Update P’s metadata, zero out memory and add P to the page table.
更新页面的元数据, 赋为0并且将P添加到 page table中
- Set the page ID output parameter. Return a pointer to P.
将 paged_id作为输出参数, 并且返回一个 Page类型的指针
-
-
FetchPgImp
传递一个参数page_id进来, 如果已经在buffer pool中, 则可以直接返回这个page. 否则, 可以从free list或者LRU淘汰一个page, 之后调用ReadPage从磁盘中获取改page_id对应的数据.
-
DeletePgImp
这个是将一个page删除掉, 但是如果该page的pin_count_大于0的话, 直接返回false, 因为代表其他在用是不可以被删除的. 如果是dirty page, 那么需要先落盘, 之后将这个page放入free list中.
-
UnpinPgImp
这个是和FetchPgImp相反的操作, 他会将一个page的pin count减一. 如果减到0了, 就需要调用LRU的Unpin接口, 让其准备被淘汰.
以上操作都需要注意很多的细节, 如对page信息的维护: pin_count, is_dirty, page_id, 是否需要reset page memory等. 一个page(frame)有三种可能位置: free list, lru, 不在前两者之中而是被pin住.
我的这部分在基本实现好后, 因为以下细节问题而只有很少的分, 需要特别注意:
- 没有加锁(预料之中过不了一些样例)
- 在UnpinPgImp中, 理解错了它 is_dirty 的意思, 以为是要flush脏页, 但其实是让我设置标志位, 否则测试中的isDirty会一直过不了
- 同样是在 UnpinPgImp中, 只对page->GetPinCount() == 0返回了true, 但其实count>0也需要返回true. 因为这个函数的语义就是把自己pin的那个unpin掉那就OK了, 而不是一定要其执行LRU的Unpin
- FlushPgImp中执行正常情况时漏掉了 return true(太粗心)
TASK #3 - PARALLEL BUFFER POOL MANAGER
这部分很简单, 主要理解它是怎么parallel的, 其实就是把上一节中的buffer pool instance弄成vector, 当调用这个数组的instance时, 他们相互之间不会有冲突, 因而实现了parallel. 而它要实现的诸多接口, 其实都可以调用buffer pool instance中的接口来实现, 它本身并不需要实现什么.
Author 姬小野
LastMod 2021-10-27