CMU 15-445笔记: Join Algorithms
Contents
概述
这一节课Andy主要介绍了介绍了数据库中实现Join的算法。和普通的算法不同的是,普通算法可以假设数据都在内存上,但是对于DBMS来说,一次操作的数据本身可能大于计算机内存,并且操作的中间数据也可能无法保存在内存上。
因此,在设计这些算法的时候,需要面向内存-磁盘结构进行设计。由于磁盘IO的时间较内存IO而言非常长,因此,磁盘IO的次数是衡量一个算法效率的重要标准;同时,对于HDD而言,算法是使用随机IO还是顺序IO,性能是有较大差异的。
总得而言,对于一个Join操作,我们要尽可能减少他的磁盘IO次数,尽可能使用顺序IO。
Join Algorithms
Join有很多种,这里只考虑inner equijoin,即等值连接。
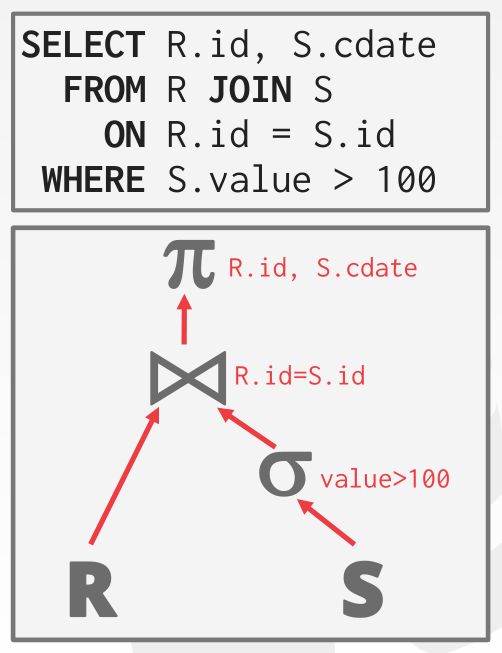
这里的join条件是 R.id = S.id。
在这个Join查询中,他不仅有Join key,还有where使用的条件,以及select选择到的列。一般where的条件会尽早地执行,从而减少tuple的数量。
一个优化是延迟物化。是指在join的时候,先忽略掉除join key以外的其它列,当join完成之后,再根据这些join key获取需要的列数据。这个优化看起来很不错,在join阶段减少了内存的占用与数据访问,提升了性能。但事实上,延迟物化提出了十几年,而vertica现在不用了,因为在分布式数据库中,join完后再一次获取数据可能从网络IO获取,会导致性能变差。
Nested Loop Join
最基本的算法,嵌套循环,绝大多数(差不多所有吧)支持Join的数据库都支持这种算法。然而它也是有三类的,分别被称为:
- Simple/Stupid
- Block
- Index
Andy先介绍了时间最长的实现来,用R的每一个tuple遍历S的N各block。
伪代码为
|
|
这样的成本是
Cost: M + (m ∙ N)
而M代表R的block数,m代表R的tuple数,N代表S的block数,n代表S的tuple数
这种方式无疑是最通俗但也是最慢的。在
Table R: M = 1000, m = 100,000 Table S: N = 500, n = 40,000
的成本中(这大概是6MB的数据),假设一次磁盘IO 0.1ms,那么需要花费约 1.3个小时。
如果把S交换到左边(事实上一般让tuple小的表在左边执行),可以优化到1.1个小时。
第二种方法是R的每个block遍历S的每个block,而block中的tuple相互Join,由于在内存上操作,因此这个的成本和磁盘IO比起来非常小。伪代码是
|
|
这种方式的成本是:
Cost: M + (M ∙ N )
例子大概用时 50s
而如果有B个block的buffer,那么使用B-2个block缓存R,1个block缓存S,1个block保存结果,则成本是:M+(M/(B-2)*N
如果B>M+2,即所有的R block都能缓存,则时间大概是0.15s
伪代码为
|
|
第三种方式是,使用index来加快join key的匹配。循环扫描成本太高了,所以有的系统会生成临时索引,Join结束之后就会删除,在Join期间使用这个索引在S中找到对应的join key,速度要快很多。
Sort-Merge Join
这种算法有两个阶段,分别是 sort 和 merge
sort
分别按照join key对两个表排序,使用上一节课介绍的扩展的merge sort algorithm。
merge
然后对两个table分别使用游标来进行Join。
如果R和S某个匹配的id里各有多个tuple怎么办?需要进行回溯,来避免漏掉;回溯只需要让S记录上一个等值id的开始位置

成本

例子成本大概 0.59s
极端情况,所有join key都相等,sort merge退化成嵌套循环。
可以和order by一起,如果order by的key和join key相等。
所有的主流数据库都支持sort-merge join,但一些小的或嵌入式的不支持。
Hash Join
同样地分为两个阶段
build
-
建立hash table,划分到不同的partition
-
但一个partition会有很多冲突
probe
-
优化:提到了bloom filters,可以用bloom filter来进行加速判断,它比较小可以放进内存
-
insert
-
lookup
-
是一个概率函数,用于判断某key“一定不在”
-
优化器会调整bloom filter的大小
-
Grace Hash Join 一种实现算法
-
当数据不能完全放在内存上时,如何进行Hash Join
-
为两个表的join key都建立hash table

-
递归分区
-
如果一个partition冲突过多的时候,可以再次进行hash从而再分区,这就是递归分区,可以递归地执行再分区

-
对于key都相等地情况,递归分区是无效的
-
-
在同一partition中,要进行嵌套循环
-
成本:3(M+N),例子大概0.45s,比sort merge jon快
总结
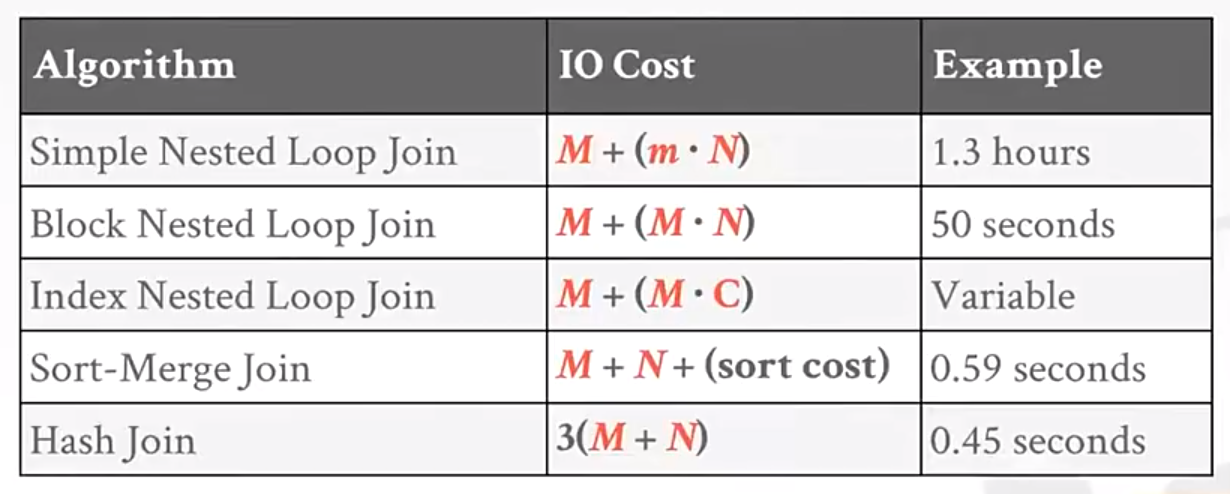
想来这个 Index Nested Loop Join性能应该不错,至少会在1s内吧
对于大多数好的数据库,都会使用Hash Join
在分布式数据库中,是类似的,不同的是用网络IO来替换磁盘IO
-
所以只要实现的接口合适,算法可以不比知道是磁盘、内存、还是网络?
-
分布式数据库如何实现 Join? - PolarDB-X的文章 - 知乎https://zhuanlan.zhihu.com/p/349420901
-
他说“实际在 OLTP 场景中,最常用的就是基于索引点查的 Index Nested-Loop Join,这样的 Join 往往能在极短的时间内返回”
-
对于OLAP和OLTP类型负载,有不同的更适合的Join算法
-
Author 姬小野
LastMod 2021-10-14