CMU 15 445 课程内容总结
Contents
15-445课程总结
目录
- 15-445课程总结
- 目录
- 课程内容
课程内容
1. 关系型数据模型
基本的关系型数据模型
DDL:定义,Create, Alter, Drop
DML: 操作, Manipulation,Insert, Update, Select
DCL:数据库控制语言,Grant,Revoke
TCL:事务控制语言,SAVEPOINT,SET TRANSACTION,ROLLBACK
2. 高级SQL
Aggregates
- AVG(col)
- MIN(col)
- MAX(col)
- SUM(col)
- COUNT(col)
Group By:把记录按某种方式分成多组,对每组记录分别做 aggregates 操作
Having:基于 aggregation 结果的过滤条件不能写在 WHERE 中,而应放在 HAVING 中。
Output Control
- order by
- limit
Nested Queries:ANY,ALL,IN,EXIST
Common Table Expressions
3. 数据库存储器
存储器层次:
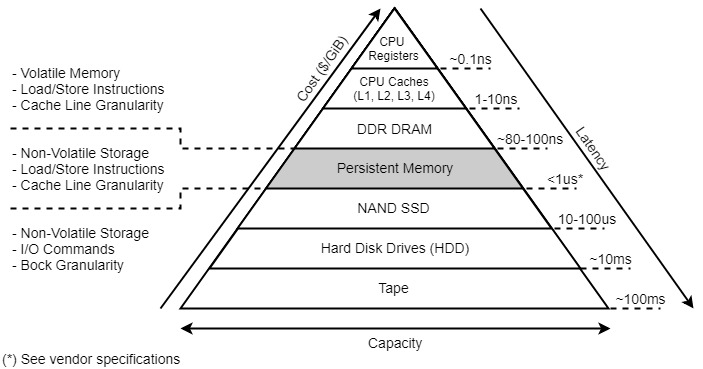
-
File Storage
- Hardware Page:通常大小为 4KB
- OS Page: 通常大小为 4KB
- Database Page:(1-16KB)
- Page Directory
-
Page Layout
- 分为两个部分:header 和 data
-
Data Layout
- Tuple Oriented(B+Tree那种):Slotted Pages
- Log Structured(LSM-Tree那种)
-
Tuple Storage 和 Layout
tuple 中还可以分为 header 和 data 两部分
-
System Catalogs
除了数据本身,DBMS 还需要存储数据的元数据,即数据字典,它们包括:
- Table, columns, indexes, views
- Users, permissions
- Internal statistics 几乎所有 DBMSs 都将这些元数据也存储在一个特定的数据库中,它们本身也会被存储为 table、tuple。
-
Data Storage Models
- 行存储:N-ary Storage Model (NSM)
- 列存储:Decomposition Storage Model (DSM)
4. buffer pools
5. hash tables
- hash table的设计
- hash函数
- hash scheme: 解决hash碰撞的机制
- 开放地址法
- robin hood hashing
- 罗宾汉是一个劫富济贫的故事, 在这里是想让节点充分地靠近它本来应该在的位置
- cuckoo hashing
- 拉链法
- 可扩展哈希(Extendible Hashing)的实现,即动态hash,有点像多级页表
6. tree indexes
看mubu的笔记吧
- B-Tree 1971
- B+Tree 1973 IBM 这节课主要介绍这个,填充因子
- B*Tree 1977 :为了减少分裂次数设计,非并发
- B^link-Tree CMU:针对并发设计
<Modern B-Tree Techniques>
在CMU 15-721中,介绍的更深入和多:BW-tree,ART,MassTree
7. 索引并发控制
讲B+Tree的并发。主要是蟹行协议和他的优化。
8. 查询处理(查询执行)
三个处理模型:
- 火山模型即迭代器模型,一条条处理和输出结果(Next)。有的操作不能一条条只能一次性如sort。
- 物化模型,一整个处理和输出结果
- 向量化模型,一批一批处理(batch)
存取方法:
- 顺序扫描(最差,有一些优化)
- index scan
- multi-index scan,多个索引一起用然后合并结果
9. 排序和聚合
- 外部归并排序 External Merge Sort
- aggregation 就是对一组 tuples 的某些值做统计,转化成一个标量,如平均值、最大值、最小值等。 通常通过 sorting或者hashing实现。
10. join算法
- Nested Loop Join 嵌套循环join。可以分为最简单的,按block的(磁盘),按索引的三种。
- Sort-Merge Join 先sort再merge,快很多
- Hash Join
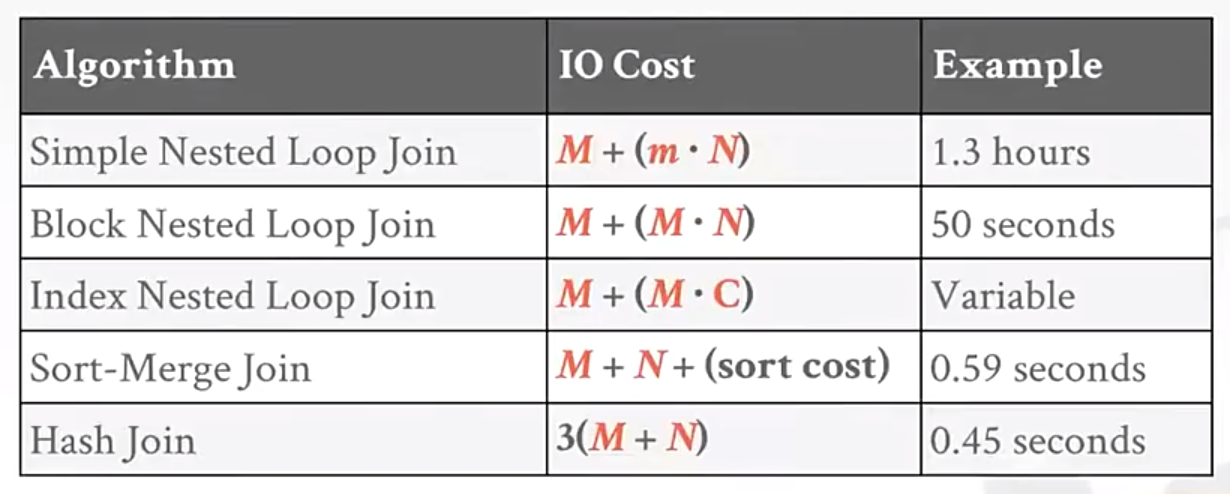
hash join的优缺点
https://www.csdn.net/tags/MtTaAg2sNzg2MjgyLWJsb2cO0O0O.html
1、优点:在做等值查询的时候,在没有hash冲突的情况下通过hash索引访问数据是非常快的
2、缺点:
2.1 哈希索引只包含了哈希值和行指针,不存储字段值,所以不能使用索引中的值来避免读取行。
2.2 哈希索引只支持等值查询,不支持任何的范围查询和部分索引列的匹配查找
2.3 哈希索引数据不是按照索引值顺序存储的,所以也无法用于排序
2.4 如果发生哈希冲突,存储引擎就必须遍历链表来逐行比较,直到找到符合条件的所有行
2.5 如果内存中无法存下哈希表,那么性能会下降很大。(相比而言merge sort更适合预读!)
merge sort的优缺点
https://www.cnblogs.com/ryanw/articles/11540774.html
优点:
- 支持不等式的连接条件。(hash join不支持)
- 经过初始的排序后,合并过程是已经经过优化的了,在生成输出行的时候要更快
- 可以利用索引。如果有索引的话,那么第一个数据集就能够避免使用排序。
- (我加的)更适合将磁盘数据预读到内存。
缺点:
- 排序的成本很高
在以下情况,优化器在连接大数据集的时候会考虑使用排序合并连接来替代哈希连接:
- 连接条件是不等式,比如:<,<=,>或者>=,相对应的,哈希连接要求是等式条件。
- 因为其他的一些操作要求排序,优化器会认为使用排序合并连接的成本更低。同时,如果有索引的话,那么第一个数据集就能够避免使用排序。但是,第二个数据集不论有没有索引,都会要求排序
相对于嵌套循环连接来说,排序合并连接和哈希连接有着同样的优点:直接在PGA里面拿数据,不需要在SGA里面反复加闩锁,然后再读取缓存,减少了不必要的I/O。
一般情况下,哈希连接的性能是要比排序合并好的,因为排序的成本很高。
但是,排序合并也有它的优点:
- 经过初始的排序后,合并过程是已经经过优化的了,在生成输出行的时候要更快
- 当哈希连接过程中的哈希表无法一次性完整构建在PGA里面的时候,排序合并的成本性能比要优于哈希连接。
11. 查询优化
略
12. 并行执行
略
13. 并发控制理论
事务:满足ACID特性
- 原子性
- 一致性
- 隔离性
- 持久性
冲突问题:
- Read-Write Conflicts (R-W):读在前写在后,可能导致不可重复读
- Write-Read Conflicts (W-R):写在前读在后,可能导致脏读
- Write-Write Conflicts (W-W):可能导致前面的W不生效。
Conflict Serializability 冲突可串行性:如果通过交换不同 transactions 中连续的 non-conflicting operations 可以将 S 转化成 serial schedule,则称 S 是 conflict serializable
并发控制协议:
- 2PL
- Basic T/O
- OCC
14. 两阶段锁2PL
- 共享锁(S锁,读锁)和互斥锁(X锁,写锁),更新锁(Upgrade锁)
- 两阶段锁协议2PL,其优缺点,S2PL,SS2PL
- 2PL无法避免死锁,需要配合死锁检测:用资源等待图判环,用Wound-Wait,wait-die策略回滚
- 其它锁协议:一次性锁协议,顺序锁,时间戳顺序↓
15. 1时间戳顺序并发控制 Basic T/O
每行数据都带有两个时间戳:
- W-TS(X):最后一次写 X 发生的时间戳
- R-TS(X):最后一次读 X 发生的时间戳
进行读写时,根据记录的W-ts和R-ts来判断是否有读写冲突,如果有冲突则需要回滚。
优点:
- 不会造成死锁,因为没有事务需要等待
- 如果单个事务涉及的数据不多、不同事务涉及的数据基本不相同 (OLTP),可以节省 2PL 中控制锁的额外成本,提高事务并发度
缺点:
- 长事务容易因为与短事务冲突而饿死(长事务操作数据时,发现被短事务先修改了。。)
- 复制数据,维护、更新时间戳存在额外成本
- 可能产生不可恢复的 schedule
可能导致脏读(读取一个正在进行的事务write的数据后,自己先commit了,前者的abort了)
可以拷贝一份数据,用于保证 Repeatable Read。
15.2乐观并发协议 OCC
会拷贝一份数据,然后进行操作,在提交前进行验证,如果验证成功,那么就可以commit。
每条数据有一个Write时间戳表示最近commit的事务的ts。
OCC分为三个阶段(RVW):
- Read Phase:追踪、记录每个事务的读、写集合,并存储到私有空间中。将 read set 存放在 private workspace 中用来保证 repeatable read,将 write set 存放在 private workspace 中用来作冲突检测。
- Validation Phase:当事务提交时,检查冲突。有Backward Validation和Forward Validation。
- Write Phase:如果校验成功,则合并数据;否则中止并重启事务
适用于读多写少的场景。
优点:
- OCC成功解决了所有读写冲突的问题
- 没有2PL的锁竞争(但有latch)
缺点:
- 在 private workspace 与 global database 之间移动、合并数据开销大
- Validation/Write Phase 需要在一个全局的 critical section 中完成,可能造成瓶颈
- 在 Validation Phase 中,待提交事务需要和其它事务做冲突检查,即便实际上并没有冲突,这里也有很多获取 latch 的成本 (锁住其它事务的 private workspace,对比是否有冲突,再释放锁)
- 事务中止的成本比 2PL 高,因为 OCC 在事务执行快结束时才检查数据冲突
16. MVCC
可以和2PL,TO,OCC结合,产生:
- MV2PL, MVS2PL, MVSS2PL
- MVOCC
- MVTO
四个部分:
- 并发控制协议
- 版本存储:Append-only, Timer-travel, Delta Storage
- 垃圾回收 (旧版本回收)
- 索引管理
注意关键词:可见性
17. logging方案
-
Failure Classification 故障分类
- 事务故障 (Transaction Failures)
- 系统故障 (System Failures)
- 存储介质故障 (Storage Media Failures)
-
Buffer Pool Policies
- Steal Policy:DBMS 是否允许一个未提交事务修改持久化存储中的数据?
- Force Policy:DBMS 是否强制要求一个提交完毕事务的所有数据改动都反映在持久化存储中? 形成四种组合,实践中主要有这两种:主要是 No-Steal + Force 和 Steal + No-Force(性能最高,基本都用这个) 如果Steal故障时需要用到undo log,如果no Force故障时需要用到redo log。
-
Shadow Paging
No-Steal + Force策略组合的实现,这种组合无法写入大于buffer pool容量的数据。
它维护两份数据库数据:
- Master:包含所有已经提交事务的数据
- Shadow:在 Master 之上增加未提交事务的数据变动 正在执行的事务都只将修改的数据写到 shadow copy 中,当事务提交时,再原子地把 shadow copy 修改成新的 master。(不知道怎么原子地修改,那么多分散的数据。。)
-
Write-Ahead Log
- Steal + No-Force策略组合的实现。
- WAL 中的每条日志记录都需要包含一个全局唯一的 log sequence number (LSN)。LSN有很多种。
- 内容:
- Transaction Id (事务 id)
- Object Id (数据记录 id)
- Before Value (修改前的值),用于 undo 操作
- After Value (修改后的值),用于 redo 操作
- WAL Group Commit
-
Logging Schemes
- physical logging:记录物理数据的变化,类似 git diff 做的事情,记录 xx page xx 偏移量上的数据发生 xx 改动
- logical logging:记录逻辑操作内容,如 UPDATE、DELETE 和 INSERT 语句等等
- physiological logging:混合策略,记录 xx page 上的 id 为 xx 的数据发生 xx 改动,不需要关心 data page 在磁盘上的布局(如offset)。是当下最流行的方案。
-
Checkpoints (下一节更详细)
- 避免wal无限增长,DBMS 需要周期性地记录 checkpoint
- checkpoints生成的频率,时机
- 生成checkpoints时是否需要暂停事务
18. 数据库恢复 Database Recovery
checkpoint
-
no fuzzy(需要停止事务)
- 停止任何新的事务
- 等待所有活跃事务执行完毕
- 将所有脏页落盘 no fuzzy还有个优化版,暂停新的写事务,但不需要等待已经开始的事务结束:
- 暂停写事务,阻止写事务获取数据或索引的写锁 (write latch)
- 维护 活跃事务表:Active Transaction Table (ATT)和 脏页表:Dirty Page Table (DPT)
-
fuzzy(不需要停止事务)实践中都是用这个方法
fuzzy checkpoint 允许任何活跃事务在它落盘的过程中执行。用一个区间CHECKPOINT-BEGIN和CHECKPOINT-END来表示checkpoint过程。
当 checkpoint 成功完成时,CHECKPOINT-BEGIN 记录的 LSN 才被写入到数据库的 MasterRecord 中,任何在 checkpoint 之后才启动的事务不会被记录在 CHECKPOINT-END 的 ATT 中。
ARIES协议(Algorithms for Recovery and Isolation Exploiting Semantics)
基于:WAL(redo undo log),fuzzy checkpoint,
通过 MasterRecord 找到最后一个 BEGIN-CHECKPOINT 记录,然后进行三个步骤:
-
分析 (analysis):从 WAL 中读取最近一次 checkpoint,找到 buffer pool 中相应的脏页以及故障时的活跃事务。
-
重做 (redo):从正确的日志点开始重做所有操作,包括将要中止的事务。
Q:如果 DBMS 在故障恢复的 Redo Phase 崩溃怎么办? A:无所谓,再重做所有操作即可,操作是幂等的
-
撤销 (undo):将故障前未提交的事务的操作撤销
将所有 Analysis Phase 判定为 U (candidate for undo) 状态的事务的所有操作按执行顺序倒序撤销,并且为每个 undo 操作写一条 CLR。CLR是 补偿日志。
ARIES核心:
- WAL with Steal/No-Force
- Fuzzy Checkpoints
- Redo everything since the earliest dirty page
- Undo txns that never commit
- Write CLRs when undoing, to survive failures during restarts
19. 分布式数据库导论
讲一些比较高层的体系思路
-
系统架构
- Shared Memory
- Shared Disk
- Shared Nothing
-
同质节点 (Homogeneous Node)和异质节点(Heterogeneous Node) 如果系统中的每个节点角色、权限相同,那就是同质节点 (Homogeneous Node);如果不同,就是异质节点。
-
数据库分区
- Naive Table Partitioning 按表进行分区,不会划分表而是将不同的表分在不同的节点上
- Horizontal Partitioning 水平分区,将表划分成没有交集的集合
-
事务协调
- Centralized Coordinator
- Middleware
- Decentralized Coordinator 可以选择一个分片作为coordinator
-
分布式并发控制
Percolator
-
副本
raft协议进行日志复制从而实现多副本容错。主副本故障可以从副本中快速选出新主副本。
20. 分布式OLTP数据库
这一节好复杂,直接看那个笔记好一点
- Atomic Commit Protocols 原子提交协议
- 2PC
- 3PC
- Paxos
- Raft
- ZAB (Apache Zookeeper)
- Viewstamped Replication
- Replication
- Replica Configuration
- Propagation Scheme
- Propagation Timing
- Update Method
- Consistency Issues (CAP)
- Federated Databases
21. 分布式OLAP数据库
略
Author 姬小野
LastMod 2022-10-21