CMU 15-445笔记: 索引
Contents
概述
本文围绕CMU 15-445中的Tree Indexes一课,对数据库引擎中的索引进行介绍和总结,点击下载课程的slide链接。本文不介绍B+Tree基本结构和操作细节,而是介绍在了解这些之后的比较和思考。
在这节课中,Andy介绍了B+Tree索引以及其后面的B-Tree family,以及其他索引类型,如聚簇索引,倒排索引,覆盖索引,联合索引等。介绍B+Tree占了最大篇幅,除了其基本内容,还详细地分析了B+Tree中leaf node的内容;并且使用PostgreSQL和MySQL进行了索引选择的实验。Andy还介绍了几种索引实现的优化方法,包括前缀压缩,批量插入,pointer swizzling(指针混写)等。
索引分类
索引是数据库存储引擎中非常重要的一个模块,数据Access Methods的内容,即访问方法,顾名思义就是如何访问数据的方法。在数据库层次结构中属于Buffer Pool只上,查询执行器之下的层次。

一般而言,有三类索引数据结构,分别是
- hash_table
- Trees
- 全文索引
而Trees又有很多类型,如B-Tree家族,Trie Tree(字典树,前缀树),Radix Tree(基数树,Trie的一种变体);其中以B+Tree为代表的B-Tree家族是最重要的,使用最为广泛的数据结构。
hash_table是一种点查询性能非常高的数据结构,在key-value类型的数据库中如Memcache,Redis使用,其在内存上维护巨大的hash_table,具有非常好的性能。它不适合进行范围查询。
B+Tree
B+Tree属于B-Tree家族,而B-Tree最早在1971年提出,衍生出了许多数据结构,如
- B+Tree 1973 IBM 这节课主要介绍这个
- B*Tree 1977
- B^link-Tree CMU
目前,B+Tree是各种数据库引擎中使用最广泛的数据结构。
B+Tree操作
Andy演示了Insert,Delete,Find三种操作
对于Insert
- https://cmudb.io/btree 演示demo 实际网址 https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
- Degree x表示最多x个指针指向下一层, 而一个node最多有x-1个key
- 空间足够可以直接插入
- 否则需要拆分节点, 然后影响上面的inner node
Delete
- 注意规则, 一个node至少需要M/2-1个entries, 如果少于这个, 就需要进行合并, 这个过程可能会重构整个树
- 实际上,不需要到达边界后就进行拆分和合并,可以维护一个阈值范围,减少拆分合并次数
在《MySQL技术内幕-InnoDB存储引擎》中,将插入和删除各分为三种情况讨论,我认为总结得很好
插入(根据Leaf Page和Index Page分为三种情况)
-
Leaf Page未满 && Index Page未满
-
Leaf Page满 && Index Page未满
-
Leaf Page满 && Index Page满
删除(根据节点与填充因子(F)的关系分为三种情况)
-
Leaf不小于F && Inner不小于F (特殊情况:删除节点是上一层的索引节点)
-
Leaf小于F && Inner不小于F
-
Leaf小于F && Inner小于F
索引页分裂
-
当page满了,分裂一定是从中间分吗?并不是。如果key是随机的,那么从中间分更好。
-
但如果key是自增的(MySQL经常使用自增键),那么从中间分是不可取的,因为后面的key都会更大。这时可以向右分裂,直接将insert的record分裂到一个新的页面。
聚集索引和辅助索引
聚集索引(聚簇索引)和辅助索引(非聚集索引)都是B+Tree索引下的分类,区别在于他们叶子节点上存储的数据的不同。
聚簇索引(clustered indexes)也称为聚集索引,聚类索引,簇集索引,聚簇索引确定表中数据的物理顺序。一般而言,在聚簇索引中,其叶子节点中保留了数据tuple,即完整的行数据。因此,使用聚簇索引搜索时,访问到了叶子节点就可以获取完整的一行数据,而不需要再根据record id去查找tuple,减少了磁盘访问次数。
在MySQL中,默认为primary key建立了聚集索引,把tuple保存到leaf nodes上;其他的secondary indexes中的leaf node则保存了primary key,再使用该primary key在主索引中进行查找,这个过程叫做回表,是一个比较耗时的操作(两次索引查找)。
聚集索引
-
叶子节点中存放的是行记录数据
-
聚集索引不一定是按照物理顺序存放,因为那样会有很大的维护成本,只需要按逻辑顺序就可以了,因为叶子节点会通过指针连接起来。
-
从另一个角度来看,由指针串连起来的有序的叶子节点,是不是即是逻辑顺序,也是物理顺序?!
-
物理顺序并不是说一个leaf page指针指向的下一个leaf page非得是和他在磁盘上的下一个page吧。
-
-
MySQL执行Explain命令会得到一个查询的执行计划
辅助索引
-
叶子节点中存放的是主键索引(聚簇索引)的key;查找到key之后还需要到聚集索引中去找完整的数据;当不需要完整数据时,覆盖索引技术可以一定程度地避免回表
-
当进行范围查询的时候,即使匹配到了某辅助索引,也可能不使用。因为还需要到聚簇索引中获取整行数据,成本较高有时还不如全表扫描。
聚集索引与堆表对比
InnoDB使用聚集索引,辅助索引利用primary key回表定位record数据;而Microsoft SQL Server则使用堆表的方式,即索引和数据分开存储,叶子节点保存record id(可能是pageid + offset/slot);
他们各有优缺点:
聚集索引的优点是对于primary查询,当访问到叶子节点时就可以直接获取数据,而不需要再跳到堆表;在进行范围查询的时候,在聚集索引一个page上的record在堆表上可能分散在多个page上,增加了IO次数
聚集索引的缺点是聚集索引的叶子节点要维护record数据,使得一个leaf page上节点更少;并且从其他辅助索引查找数据还需要再经过一次聚集索引进行查询,会增加不少的IO次数,这个叫做回表。
堆表的优点是从索引上找到的record id不需要经过聚集索引,而可以直接定位到堆表的具体位置
堆表的缺点是范围查询节点可能较分散;以及当record需要进行更新时,会更换在堆表的位置,这时需要更新索引的record id(走一遍索引),适合更新少的负载(如OLAP)
其他索引应用技术
联合索引
对表上的多列进行索引;符合前缀索引原则。
覆盖索引
从辅助索引中就可以得到查询的记录;这样就不需要进行回表
前缀索引
使用key的前缀作为索引,使得一个page容纳更多的节点。
例如用邮箱的前7位作为索引,可以节省很多空间,牺牲了一些前缀重复key的查询性能。这之间需要有一个良好的权衡。
索引选择
Cardinality值
该值的含义是索引中唯一值的数目的估计值,在InnoDB中是在一定条件触发进行采样得到的值;它表示的是索引的选择性,是在存储引擎层实现的。
对于优化器来说,他会尽量选择Cardinality值接近全部record数目的索引,因为这样区分度高。
对比而言,如果对全国人信息的表建立一个以性别为key的索引,那么它的C值为2,还需要进行大量的遍历来进行区分。
辅助索引的回表影响索引的选择
对于一些范围查询,即使有对应的辅助索引,得到primary key之后还需要大范围地在聚集索引中查询,因此还不如直接全表扫描
索引提示
如果索引非常多,那么优化器在进行评估的时候花费的时间可能较长,还不如直接给出索引提示
优化器可能错误地使用某索引,导致性能非常差
强制执行索引
可以强制存储引擎使用某索引
B+Tree和B-Tree的区别
Andy说PostgreSQL文档说它使用B-Tree, 但实际使用的是B+Tree,Andy说这个是想说B-Tree和B+Tree总是混用, 说B-Tree也可以代表B+Tee;当然,B+Tree和B-Tree是有显著的区别。
区别:
-
有k个子树的中间节点包含有k个元素而B树中是k-1个元素
B+树
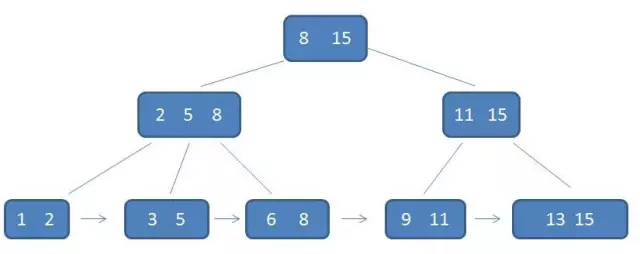
B-树
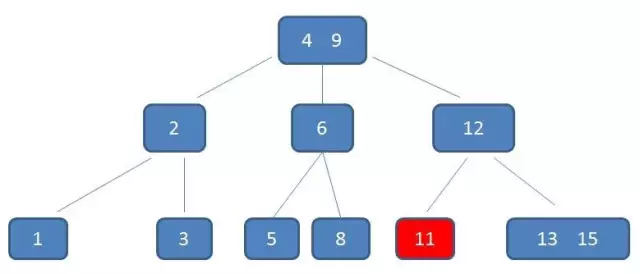
-
B+树每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
-
B+树每个父节点的元素都出现在子节点, 并且是子节点的最大元素(或者下一个page的最小元素).
-
B+树的叶子节点用有序链表链接起来了, 因此在查询一个区间的时候不需要通过中序遍历去查找
-
B树所有结点都带有卫星数据, 而B+树只有叶子节点带有卫星数据.
需要补充的是,在数据库的聚集索引(Clustered Index)中,叶子节点直接包含卫星数据。在非聚集索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针。
-
B+树比B树更加矮胖, 因为它的中间节点没有卫星数据, 因此能容纳更多的中间节点, 使得磁盘IO次数更少.
-
B+树性能不稳定, 因为它只要查找到结点就可以, 而B+树每次都需要查找到叶子节点.
-
B树的范围查询很繁琐, 因为需要经过中序遍历. 而B+树可以通过指针快速地进行范围查询.
-
B-Tree在多线程场景下性能较差, 对锁方向的要求更多, 这是B-Tree性能不如B+Tree的重要原因
B+Tree leaf node的细节
叶子节点上保留了什么数据?Andy在课上重点分析了这个问题,一般而言有两种

-
第一种: value是 record ids
- 不管是primary还是secondary index, 叶子节点上的value都是record id
- PostgreSQL是这种代表;
- SQLServer, Oracle默认是第一种, 可选第二种
-
第二种: value就是tuple 数据
-
mysql, SQLite就是这种, 但这是主要(primary)索引
-
对于secondary index, 不会保留数据副本, value和第一种一样, 都是record id
-
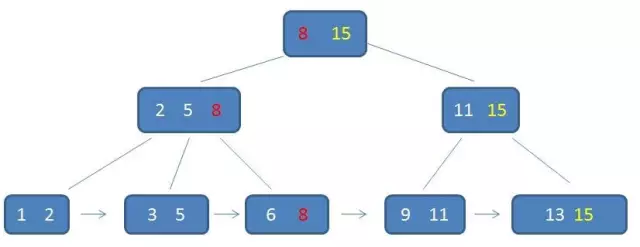
在视频中,Andy举了一个奇怪的例子
-
PPT里B+Tree的一个图, 奇怪的例子
- 图
- 在这个例子中, 5在inner node中出现了, 但是在leaf nodes中没有出现,这看起来是一种bug
- Andy说这是可以的, 进行搜索的时候, 会一直搜索到leaf node, 然后发现没有5, 而inner node的5可以作为索引但是实际不存在
- 这个情况可能是进行删除时删除了leaf node上地数据但还没有来得及删除inner node地数据(或者其他情况,因为不删除中间索引也不会影响结果)
- Andy提示,不能根据索引inner node的数据来判断一个key是否真的存在!
- 图
在一个leaf node里,key和value(tuple或者record id)是如何组织的呢?
有多种组织方式,如
-
key和value连续
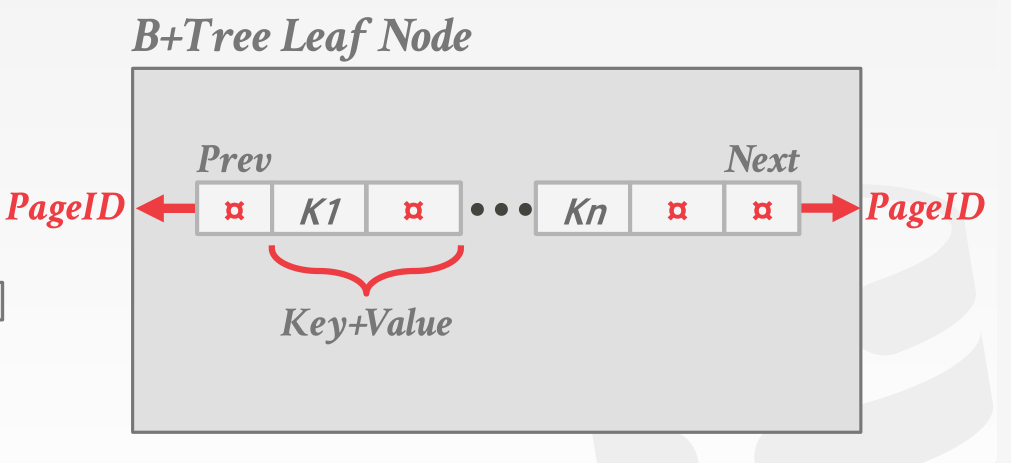
-
key和key之间连续,而每个key后面都有一个offset指向value的位置
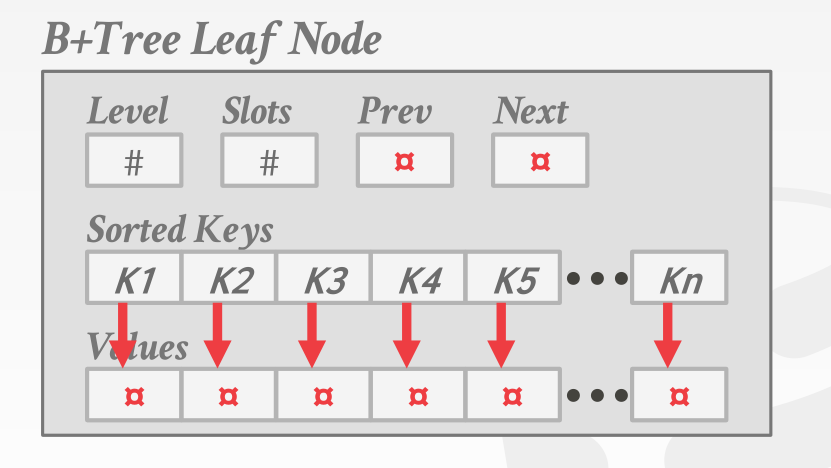
在这里,最主要的问题在于key和value的长度是不确定的。
一本好书: Modern B-Tree Techniques
这是一本介绍现代B-Tree技术的书,内容非常丰富,探索了一些复杂场景,如
-
node size

-
可以使用一个buffer pool管理page
-
另一个buffer pool管理index, 设置为不同的node size
-
-
merge threshold
-
当没有达到半满状态, 就可能需要进行合并
-
但是平凡的合并拆分(阈值)的代价比较大, 所以可以进行一个权衡, 不需要马上合并
-
如果没有及时合并, 那么树可能变得不平衡; 需要垃圾回收机制调整树(重写树)
-
-
variable length keys
-
变长的key

-
现在基本没有人用第一种方法了
-
也没什么人用第二种方法了; why?
-
第三种padding, 是填充如填充0, 会浪费空间, postgreSQ使用了这种方式, 例如设置varchar(2012), 不满足这个长度的就填充
- 如果存储了超过限制的数据, dbms可能把超出的部分截掉
-
第四种: 间接映射, 更常用的方式
-
为当前page的key保存offset, 重点是"他们在同一个page"
-
offset是定长的

-
-
-
-
non-unique indexes 非唯一索引
-
两种方式

-
第一种, 在key后面append record id, record id由page id + offset组成, 是unique的
- 不可以用于PostgreSQL
-
第二种是违反了B+树的一些规则
- 将多出的部分放到overflow叶子节点上, 是垂直扩展而不是水平

- 将多出的部分放到overflow叶子节点上, 是垂直扩展而不是水平
-
大多数选择使用第一种
-
四种优化方式
-
前缀压缩
-
后缀截断
-
当字符串前面的字符就可以判断向左还是向右时, 是不需要使用后缀的, 因此可以截断
-
不过效果没有"前缀压缩"好
-
-
bulk insert: 批量插入
- 已获取所有数据的时候, 可以自下而上地建立索引, 而不需要一个一个进行插入
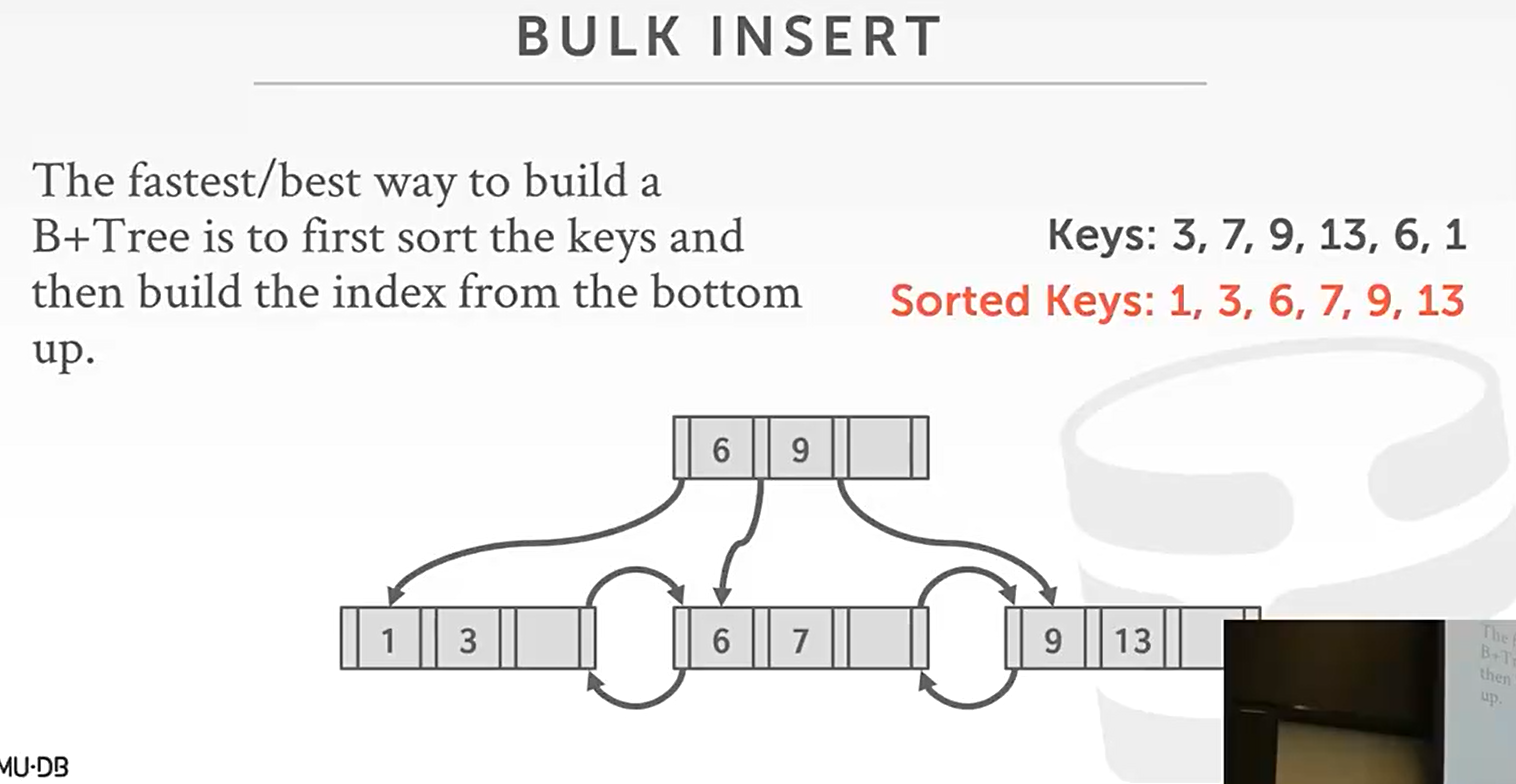
- 已获取所有数据的时候, 可以自下而上地建立索引, 而不需要一个一个进行插入
-
pointer swizzling: 指针混写
swizzling是搅动, 混合的意思(鸡尾酒), 这里指page的指针可以是page id也可以是Page(真实的指针)*
-
node中地指针并不是指原始指针, 而是page id

-
不过这样的代价很高, 因为page id还需要经过buffer pool去将这个page id转化再去获取page
-
可以在一个page pin住地时候, 保留他们的Page*, 因为这种情况他们在内存上的位置不会改变
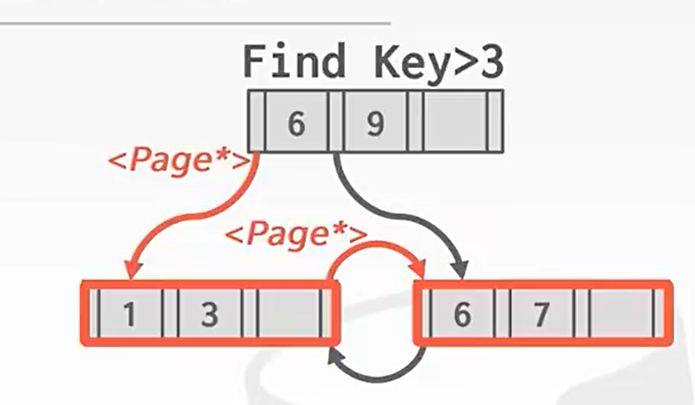
-
哈希索引
看起来哈希索引不适合MySQL,但其实它是存在的。因为在一个存储引擎中,并不是只能有一个索引结构,每种索引都有其特点优势,因此在某些特定的情况下,哈希索引也能够有很好的性能,例如当你绝大多数查询都是点查询时。对于优化器来说,当使用哈希索引的预估成本更小时,他就会选择使用哈希索引。
自适应哈希索引:这是InnoDB自身创建并使用的,DBA不能干预;只能用来搜索等值的查询
全文索引
我们在浏览器上进行搜索时,搜索引擎就是通过全文索引来给我们找到想要的网页。
InnoDB也支持全文索引,在支持前,很多用户因为InnoDB不支持它而使用MyISAM。
使用倒排索引技术来实现。
Author 姬小野
LastMod 2021-10-08