CMU 15-445笔记: 数据存储
Contents
要介绍的内容
-
顺序访问、随机访问
-
mmap以及其为什么不行
因为他的页面会收到操作系统的缓存管理,内和缓冲区高速缓存
-
直接IO和裸IO的区别,裸IO绕过文件系统
-
一个数据库表在磁盘的文件布局或模式,《mysql45》中介绍了mysql的方式,以及数据回收的方式
计算机存储体系
介绍计算机存储的分层体系,以及各体系速度的比较。
一般我们谈到数据库的存储首先会想到磁盘,但是数据库涉及到的存储结构远远不止磁盘,还有内存,磁盘分为HDD,SSD,CPU Caches,非易失性内存,甚至网络存储。
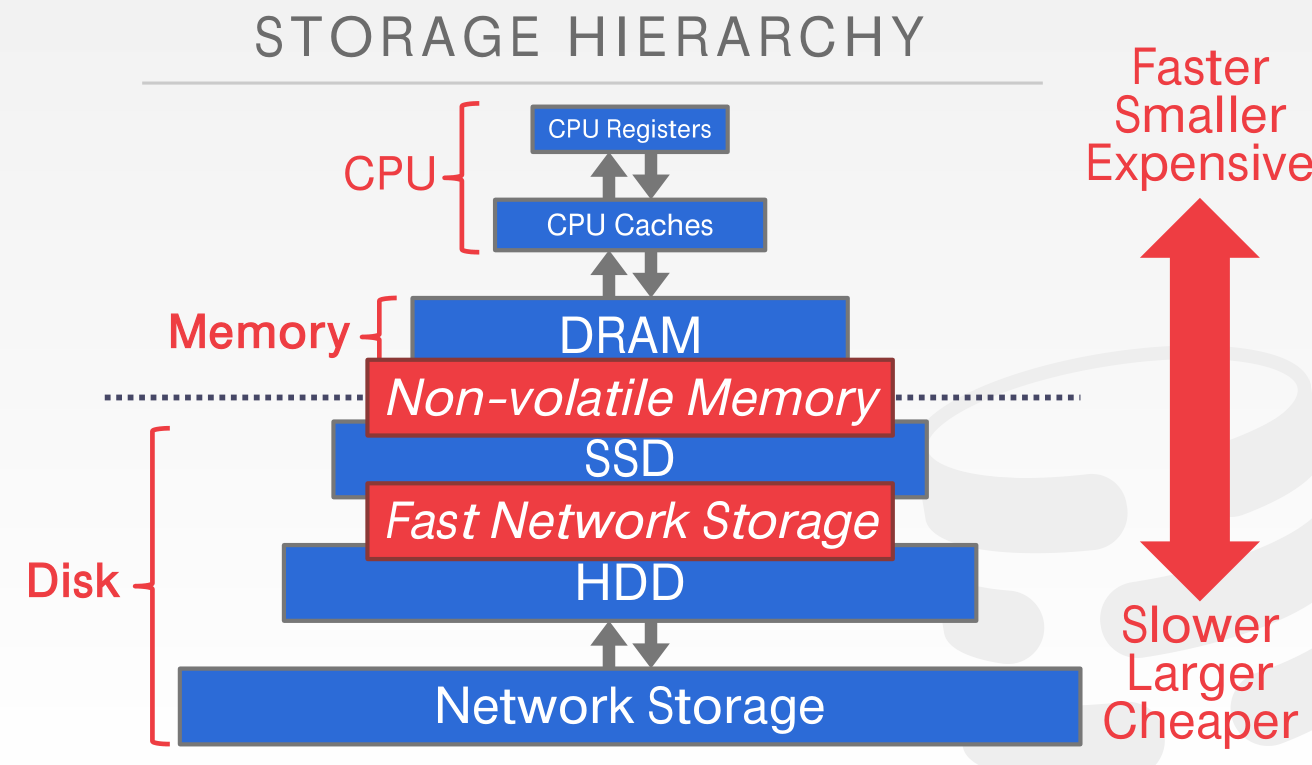
以sec时间来对比他们访问时间的差别

并且,对于HDD磁盘而言,顺序写和随机写的性能差距可能有百倍的差距。因此,除了有B+Tree这种随机读写的存储引擎外,还出现了另一种LSM-Tree结构的存储引擎,它的主打优势就是将随机写合并成顺序写,从而最大化写性能,牺牲了一定的读性能。
mmap与直接IO
介绍数据库如何将磁盘上的数据映射到内存。
O_DIRECT是open的一个参数,表示使用直接IO的方式打开文件。
mmap是操作系统提供的内存映射技术,他有多种模式,其中一种就是将磁盘文件以页的方式映射到虚拟内存空间,在修改内存上该页的同时,也能修改磁盘(操作系统管理写回)。然而,它的页面受到操作系统维护的内核缓冲区高速缓存的管理。而在DBMS中,为了最大化性能,往往需要DBMS维护自己的一套缓存,因为DBMS才能真正了解自己的负载从而缓存合适的页面。
这样就导致mmap和DBMS缓存同时缓存一个页面,浪费了内存(冗余)且增加了CPU负载(内存拷贝)。
在课程中,Andy多次表示对mmap方式的数据存储的hate,他说rocksDB fork自leveldb,然后第一件事就是替换了mmap。PS. 所以为什么LevelDB选择使用mmap呢?为了方便吗?
使用直接IO是一个更好的方式,因为直接IO不会使用到OS提供的缓存,DBMS可以自己维护一套缓存。
事实上还有另一种形式,那就是直接原始磁盘访问,即绕过OS的文件系统转而实现自己的文件系统。这种方式有一定的性能提升(幅度不大),不过很麻烦而且可移植性差,因此大多数DBMS都不使用这种方式。
数据库在磁盘的组织方式
Andy从以下几个角度介绍了数据库在磁盘文件中的组织方式:
- File Storage
- Page Layout
- Tuple Layout
- Data Representation
- System Catalogs
- Storage Models
分别进行介绍
File Storage
主要是指数据库在磁盘中的文件组织方式,例如是整个数据库只有一个文件,统一管理,还是每个table都有一个文件。在MySQL 5.6.6版本之后,默认是为每个表数据分配一个独立地文件,当drop这个表时,这个文件就会被删除。而在更早的版本,则是放在共享表空间里,当drop表时,并不会删除(回收)这段空间,而是会将这段空间标记为可复用,从而让其他的表使用。
DBMS存储在磁盘中的page除了有普通page外,还有一种特殊page,那就是directory pages。这些目录pages记录其他page的使用情况,可以当作是其他page的元数据。DBMS需要保证directory pages和data pages的同步。
Page Layout
这一节介绍的是在一个Page中,数据的布局。
数据并不是简单地存储在page上的,除了tuples数据本身,一个page还包括header,即一些元数据:
- Page Size
- Checksum
- DBMS Version
- Transaction Visibility
- Compression Information
例如,Checksum可以用来判断数据是否损失,DBMS Version用来标识当前DBMS的版本。
Data Layout
介绍Page中header以外的数据是如何组织的
LSM-Tree是一种记录操作日志的存储引擎,而B+Tree则是一种记录数据本身的存储引擎。
对于这两种引擎,他们的page的layout是不一样的。如何管理这些tuple,使得他们在Insert,Delete的时候有更好的性能?
LSM-Tree的page就不要考虑Insert, Delete等情况,因为它的page是只读的,任何更新都是以追加日志的模式添加的,因此在page内不会出现新的tuple添加或旧的tuple被删除。
对于B+Tree的page,就需要考虑这种情况。例如,可以让所有的key-value tuples连续地存储,但是这样如何找到某一个key-value呢?可以在page的前面添加slot array,每一个tuple对应一个slot,slot存储了某个tuple在page中的偏移。因此,定位一个tuple可以通过 pageid + slot的方式进行定位。
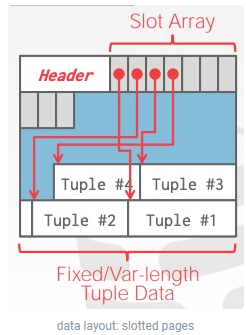
从图中可以看到,slot是从header后开始增长,而tuple则是从page的尾端增长的,他们同时向page中间增长,这样就避免了不知道预分配多大的slot array的情况。
slot是定长的因此可以很方便地进行索引。而slot是保存一个tuple保存在page中的偏移,所以即使tuple不是定长的也可以工作。
LSM-Tree结构的page是如何组织的呢?可以看LSM-Tree的经典实现leveldb的原理介绍。
Tuple Layout
tuple也并不是简单的数据,他也包括它的元数据。例如,tuple粒度的权限和并发控制,tuple是定长还是可变长度等等。

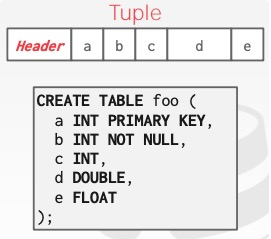
如何唯一标识一个tuple?很多数据库使用record id来标识一个tuple,这个record id可以由page id + slot/offset来表示。
tuple即是一行数据,一行数据会有多列属性,并且属性的类型是有很多的。有的属性如int,是定长的,而有的属性如varchar是不定长的,那么如何存储定长与不定长的属性呢?
System Catalogs
Storage Models
MySQL数据存储
mysql实战45讲中第13讲的内容可以介绍一下
表与文件的关系
mmap或是直接IO
Author 姬小野
LastMod 2021-10-06