《Architecture of Database System》- 数据库系统架构
Contents
概述
本博文主要介绍数据库系统的基本架构,内容主要包括对《Architecture of Database System》的总结和理解。本文只是对数据库基本架构进行介绍,各个模块更详细深入的内容可以看本站点 数据库tag 的其它相关内容。
Joseph M. Hellerstein, Michael Stonebraker, James Hamilton. Architecture of a Database System. Foundations and Trends in Databases, 1, 2 (2007).
Architecture of Database System是一篇2007年发表的论文(或者书),一共119页,从体系结构方面对数据库的实现原理进行了介绍。其作者都是在数据库领域非常著名的研究者,Joseph M. Hellerstein, Michael Stonebraker参与了一本叫做《Readings in Database Systems》的小书(也叫redbook)的发行,截至目前,已经出版了第五版,这本小书分为十来个章节,分别简要介绍数据库领域的经典论文,从传统的RDBMS到New DBMS Architectures,是非常好的论文阅读扩展方向。
Michael Stonebraker与2014年获得了图灵奖,他参与的项目有Aurora,C-Store,H-Store,Morpheus,以及SciDB系统等,同时也是以下数据库公司的创始人:Ingres, Illustra, Cohera, StreamBase Systems, Vertica,以及VoltDB,可以说是数据库领域的超级大牛。
这篇文章从进程模型、并行体系结构、关系查询处理器、存储管理、事务、共享组件等方面对数据库架构进行了介绍。虽然有的内容较老,新技术不断涌现,但这篇论文仍不失为了解数据库体系的绝佳材料。
基本架构
一个DBMS主要包括如下组件
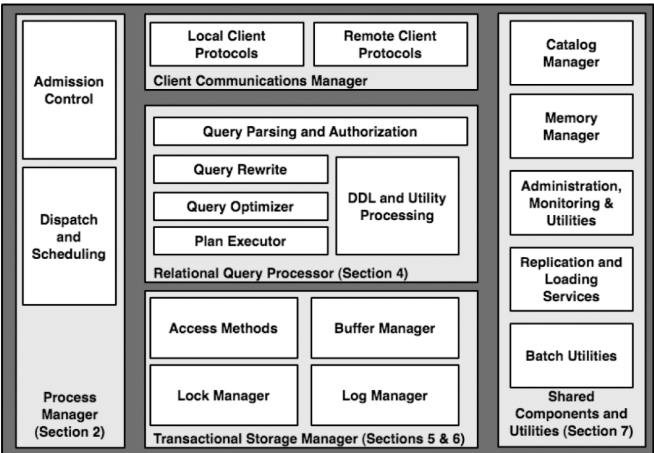
模块较多,但主体模块如下:
-
通信管理器
-
通过ODBC/JDBC来连接DBMS(二层架构)
-
也有三层结构,客户端连接一个中间层(代理层),中间层和DBMS连接
-
-
进程管理器
-
准入控制
-
进程模型,如多进程模型、线程池等
-
-
查询处理器
-
查询解析器
- 词法分析,语法分析
- 权限管理
-
查询优化器
- 为查询生成性能最优(但不一定)的执行计划
- 进行代价评估
-
查询执行器
- 调用存储引擎的接口,执行查询
-
-
存储管理器(即存储引擎)
-
缓冲管理器:磁盘和内存的缓冲管理
-
事务管理器:ACID事务
-
日志管理器:持久化,故障恢复
-
锁管理器:解决并发冲突
-
-
目录管理
点评:想要实现一个功能较完整的哪怕是玩具级别的DBMS也不是件简单的事,包含的模块太多了。了解理论简单,但实现起来细节爆炸式增长。
进程模型
介绍数据库,怎么讲起进程模型来了?
数据库也是运行在操作系统上的软件,所以是绕不开操作系统的,任何建立在OS上的应用程序,都需要考虑其进程模型,以及了解操作系统的进程原理,以最大化软件性能。
操作系统的进程与线程
操作系统的进程和线程主要分为三类:
-
操作系统进程
-
操作系统线程(内核线程)
-
轻量级线程(应用层次)
-
仅在用户空间调度而没有内核的参与,切换快速;
-
当发生中断操作时,整个进程都会中断;可通过某些方式避免
-
只接受无中断的异步 IO 操作
-
不调用可以导致中断的系统操作
-
-
纯粹的轻量级线程并不好,更好的是 M:N 的线程模型,如 Go 语言的Goroutine实现方式
-
DBMS的进程/线程模型
而DBMS的进程/线程模型是不固定的,每个系统都有其实现方式,主要分为以下几种类型
-
多进程模型
-
每个 DBMS worker 拥有一个进程,也可以实现成进程池
- DBMS worker 是指DBMS 中为客户端工作的线程
-
优点是开发简单,调试简单
-
缺点是这种模型需要广泛使用共享内存,因为需要定义很多共享的数据结构,如锁机制,缓冲池;
-
在现在应该基本不使用这种模型了吧,应该主要使用线程池了。
-
-
多线程模型
-
每个 DBMS worker 拥有一个线程,以线程池的方式提供服务
-
优点是线程共享一个进程空间
-
缺点如下
-
操作系统不对线程提供溢出和指针的保护,导致一个线程可能影响其他的线程
-
多线程调试困难
-
兼容性不好,因为不同的系统在多线程接口上的实现不是很统一(现在应该比较统一了)
-
-
进程模型的选择依赖于共享空间,因为不同的进程模型在共享空间上的表现是不一致的,而这需要开发人员权衡利弊
-
磁盘 IO 缓冲区
-
磁盘 IO:缓冲池
-
日志 IO:日志尾部
-
-
客户端通信缓冲区
- 客户端是 pull 模型,通过发送 SQL FETCH 请求不断地获取结果元组
-
锁表
- 被所有 DBMS worker 共享
准入控制
多用户系统负载不断升高,吞吐量将达到上限,因此不能无限地允许客户端连接。任何好的多用户系统都有准入控制机制,在系统没有充足资源的情况下,新的任务不被接受。如果拥有一个好的准入控制器,系统将在过载情况下发生比较优雅的性能衰退:事务延迟将随着到达率的增加而适当增加,但吞吐量一直保持在峰值。
准入控制需要控制客户端连接数在一个临界值之下,避免网络连接数这类资源过度消耗(socket资源)。在 DBMS 关系查询处理器上实现,准入控制器在查询语句转换和优化完成后执行这一步操作,然后可以估算这个语句需要的资源,然后根据资源消耗来决定是否让它执行。
并行架构:进程和内存协调
主要分为三类:Shared-Memory 共享内存、Shared-Nothing 无共享、Shared-Disk 共享磁盘。
Shared-Memory 共享内存
它是一种单节点结构,区别于共享磁盘和无共享模式的『多节点』。包含两种,SMP(SMP: Symmetrical Multi-Processing 对称多处理器) 和 多核系统 的统称。
基本结构:一个Ram,一个Disk,多个CPU(或多核)
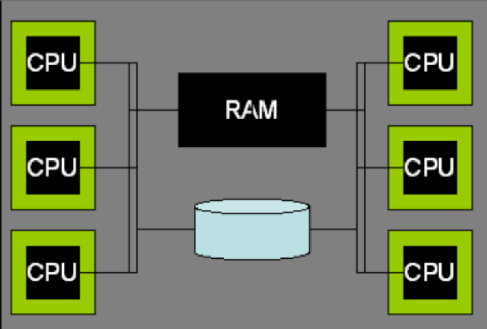
SMP架构也是目前最普遍的一种单机架构,像平时用的服务器或者个人电脑大多数都是 SMP,多核 CPU+共用内存。当然,严格来讲这里的处理器是物理处理器,一个有多核的处理器架构和这个是比较类似,也可以算作 SMP 架构。
Shared-Nothing 无共享
mapreduce,TiDB等系统(Google 系)就是这种 Shared-Nothing 架构,以低成本的方式构建超大规模分布式集群,每一个服务器都是廉价的。
结构
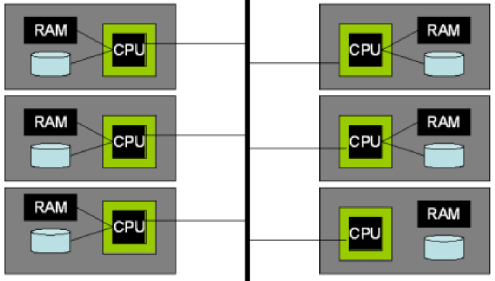
无共享架构里要解决的问题是节点故障问题,有以下三种方法
-
如果有一个节点故障,就停止运行所有的节点(牺牲可用性)
-
允许正常的节点上继续查询,跳过故障节点(数据的完整性得不到保证)
-
采用冗余方案,节点故障后通过副本恢复(目前最常使用的方法)
-
同步复制 / 异步复制
-
Raft/Paxos 多副本
-
目前,无共享架构非常普遍,具备无与伦比的可扩展性和低成本特性。
Shared-Disk共享磁盘
多个处理器,具有独立的内存(不可相互访问),共享磁盘。这种架构非常适合 存储区域网络(SAN: Storage Area Networks)。什么是存储区域网络?概念及应用一篇学会 - ielab的文章 - 知乎https://zhuanlan.zhihu.com/p/339576871
这个架构看起来很像Aurora那种Shared-Storage架构,但还是有一些区别的。
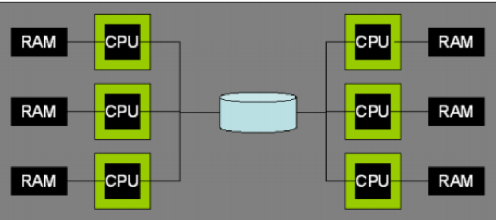
它的优点是:单个 DBMS 处理节点发生故障不会影响其他节点访问整个数据库,因为数据保存在磁盘上
NUMA 非均衡内存访问
全称:NUMA: Non-Uniform Memory Access,它属于无共享系统和共享内存系统的中间地带,每一个内存和 CPU 相结合的子集通常被称为一个 pod(k8s 也有 pod 的概念),NUMA 集群没有成功取得任何显著的份额。
Shared-Storage (补充)
shared-storage(共享存储),意为将本地盘存储换成了分布式共享存储。
PolarDB-X官方有一篇文章介绍相关内容:数据库架构杂谈(1)云数据库架构 - PolarDB-X的文章 - 知乎https://zhuanlan.zhihu.com/p/321353390:
- 现在的分布式数据库基本分为两类架构:shared-storage(AWS系) 和 shared-nothing(Google系)
- Aurora(对标 spanner)是 shared-storage 的代表;PolarDB 也是这种架构
- Aurora 是基于 MySQL 的
- Spanner(同 TiDB,CockroachDB)是 shared-nothing 的代表
TiDB是属于shared-nothing还是shared-storage数据库? - 申砾的回答 - 知乎https://www.zhihu.com/question/55613676/answer/145770653:
-
这个回答作者是 PingCAP 的一名开发人员,应该比较可信
-
有的文章说 TiDB 是 Shared-Storage,我不太认可
关系查询处理器
DDL和DML
-
DDL是数据库定义语言,如Create Table,Create Index
DDL通常并不是关系查询处理器处理的,而是通过存储管理器和目录管理器来实现的。也有例外。
-
DML是数据库操作语言,负责增删改查如:INSERT, DELETE, UPDATE, SELECT
查询解析
解析的目的
-
检查该查询是否被正确定义(语法、语义分析)
-
解决名字和引用(处理别名,转化成数据库内部的完整表示)
-
将查询转化为优化器使用的内部形式(即中间表示,例如抽象语法树,有向无环图)
-
检查用户是否有权限执行这个查询
一个查询解析的流程
-
解析器首先将from后面的表名规范化为:“服务器. 数据库. 模式. 表名” 或者 “数据库. 模式. 表名”
-
#问题 模式是什么?数据库后面不就是表名吗?不同数据库有不同的层级结构,有的可能没有模式吧。模式应该是schema,在mysql上就是DataBase
-
好奇怪,在Google上搜索“表名规范化”搜到的根本不是这一类东西。。。都是表的规范命名方法;说明这个名词也比较老了现在用的不多了
-
-
规范表名之后,查询处理器调用目录管理器(管理表的元数据),看表是否被注册
-
类型检查,看类型是否正确或兼容(跟编译原理一样,解析部分其实就是编译的前端部分)
-
权限检查。有时候这部分在运行的时候进行,因为权限有可能跟值有关。
-
被传递到重写模块进行重写。
查询重写
查询重写模块,或重写器,负责简化和标准化查询,而无需改变查询语义。查询重写模块通常输出一个查询的内部表示,这种输出形式和它接受作为输入的内部格式相同。并不是表面的SQL语句重写,而是对中间表示重写(如抽象语法树),要么发生在查询解析的后期阶段,要么发生在查询优化的前期阶段(总之是两阶段之间)。
重写职责
-
视图重写
重写器会从目录管理器中检索出视图的定义,将视图转化为实际的表;这个过程是递归的(视图可嵌套),直到表达式里只有表,没有视图
-
常量运算表达式
简化表达式,如将 x < 10 + 2简化为 x < 12
-
谓词逻辑重写
- 如谓词逻辑 x < 10 AND x > 10,这种就直接重写为 FALSE;(有点像上一个)。
- 上面例子看上去很奇怪,但其实谓词有时候隐藏在视图中,而外部用这个表看不到,所以可能出现上面的特殊情况。
- 谓词逻辑重写还可以通过谓词传递性引入新的谓词,从而增加了优化器选择方案的能力。
-
语义优化
-
子查询的平面化等启发式重写
点评:查询重写在解析器和优化器之间,其行为表现得非常像优化(事实上,他的目的就是优化),所以我觉得也可以将其归类到优化器中,事实上很多其它介绍数据库架构的文章是这么做的。但是,视图重写这一个功能,如果放到优化器中,字面意思上容易让人感到困惑,而放到“查询重写器”中,就让人觉得很有道理,所以查询重写器的存在还是很合理的。
查询优化器
优化器是数据库中最复杂的模块之一,尽最大可能生成最低成本的执行计划(但往往不一定能),它决定对特定的查询使用哪些索引、哪些关联算法、操作执行顺序 从而使其高效运行。
『Selinger 的论文』是查询优化领域的圣经,现在的系统在许多不同的角度显著地扩展了这篇论文的工作。
扩展的主要方向有:
-
计划空间
-
选择性估算
- 进行代价估算,从而选择优化的方向
-
搜索算法
-
有动态规划方法,也有自顶向下的搜索方法
-
MySQL 引擎的查询优化器在最后的检查是完全启发式的,而且大部分依赖于利用索引和键/外键约束
-
-
并行
-
自动调优
查询执行器
查询执行器操作一个完全具体的查询计划。
查询计划通常是一个把很多操作连接在一起的数据流图,这些操作封装了基本表的访问和各种查询方法,Graefe 的查询执行综述论文似乎很牛逼。
迭代器,查询执行器中比较重要的一个组件,迭代器的一个重要性能就是,它们连接了数据流和控制流。
数据在哪里?元组在内存中是如何存储的?数据是如何在迭代器之间传递的?
数据修改语句
- 『万圣节问题』:更新和查询同时存在,更新会对之前更新过的行再次更新直到不满足条件
- SQL 语义禁止这种行为:一个单一的 SQL 语句是不被允许“看到”自己的更新的
数据仓库
简单介绍了数据仓库这种OLAP类型的数据库和传统数据库技术的区别
-
位图索引
-
快速下载
-
物化视图
-
rollup (补充)
-
ad-hoc
-
如何理解 大数据、数据仓库领域的ad-hoc这个词? - Jerry Liu的回答 - 知乎https://www.zhihu.com/question/48734970/answer/490288838
-
-
雪花模式
-
星型模式
访问方法/索引
这部分就是索引部分,主要是B+Tree,HashTable等索引数据结构,这部分内容较多,之后会写一篇介绍数据库索引的博客,链接:
存储管理
存储管理主要是基于“空间局部性”和“时间局部性”原理。
-
空间局部性
-
DBMS 不使用操作系统提供的接口,而是自己直接控制数据存储到磁盘设备中,从而控制数据的空间局部性。
-
预读取针对的是空间局部性,解析器了解接下来要读取哪里的数据,在真正读取之前就先将数据读取到缓冲上。
-
-
时间局部性
- 缓冲池(buffer pool)针对的是时间局部性问题:被访问的页面,在短时间内很可能再次被访问。因此将其暂时保存到内存上。
事务:并发控制和恢复
事务存储管理器四大组件
-
锁管理器:并发控制
-
日志管理器:事务恢复
-
IO缓冲池:利用局部性加速访问 5. 存储管理
这一组件相对其它三个组件比较独立;其他三个组件的相互依赖比较明显
-
组织磁盘数据的访问方法(即索引)
重要概念
-
ACID
-
原子性
-
一致性
-
隔离性(可以大作文章)
-
持久性
-
-
可串行化
-
并发控制技术
-
两阶段锁 2PL
-
多版本并发控制 MVCC
-
乐观并发控制 OCC
-
-
事务隔离级别 多套体系,普遍了解的是第一种(SQL标准),所以了解其他更完善的体系很有价值(两篇相关论文)。
- A Critique of ANSI SQL Isolation Levels
- Generalized Isolation Level Definitions
重要结构
-
锁(lock)和锁存器(latch)
lock和latch都是锁的功能,但是在数据库中有很大区别。lock的服务对象是事务,在事务并发中使用。而latch的服务对象是线程,在线程并发时使用,更接近操作系统中的锁,是更底层的保护内存数据结构的锁。
-
日志管理器
-
索引的锁和其日志
共享组件
-
目录管理器
管理表等的元数据,目录
-
内存分配器
DBMS可以选择使用不同的内存分配器(如tcmalloc,jemalloc等)进行内存分配
一个SQL的完整生命周期
-
一个SQL从客户端编写,并发送到服务器的数据库系统上
-
DBMS的通信管理器接收到客户端的SQL之后,使用进程管理器为其分配一个处理线程
-
查询被交给查询处理器,对SQL进行解析与优化处理
-
解析SQL,词法分析,语法分析,生成中间表示
-
进行查询重写,查询优化,生成查询计划
-
查询执行器对查询操作进行执行,如:连接、选择、投影、聚集、排序;
-
-
查询会从DBMS的存储管理器中获得数据
- 存储管理器包括管理磁盘数据的基本算法和数据结构,比如表和索引
- 存储管理器还包括缓冲管理器,事务管理器,日志管理器,锁管理器
-
将SQL查询结果通过通信管理器返回给客户端
Author 姬小野
LastMod 2021-08-22